Transformer Models Explained: The Backbone of Modern AI
The LEGO of AI: Building Transformer Models
Introduction
From Toys to Tech: Why Transformers Matter
Imagine you’re building with LEGO bricks, snapping together a wall, a window, a roof to form a house, and with more pieces, an entire city. Transformer models in artificial intelligence work similarly: they’re not one massive structure but a collection of smart, small components, each designed for a specific task, connecting to create something extraordinary.
Why Are Transformers a Big Deal?
Transformers have revolutionized AI, powering innovations like:
ChatGPT: Answering questions with human-like understanding.
Google Translate: Enhancing multilingual communication.
DALL·E: Transforming text into stunning artworks.
GitHub Copilot: Accelerating code writing for developers.
Before transformers, AI struggled with long sequences, context, and scalability. Now, transformers enable machines to not just process but understand information.
What You’ll Learn in This Post
This blog will guide you through:
A brief history of AI’s evolution to transformers.
A step-by-step breakdown of how transformers are built, like LEGO bricks.
Real-world applications with vivid examples.
The power of the attention mechanism.
Common myths and pitfalls to avoid.
A visual explanation of data flow in transformers.
By the end, you’ll understand what a transformer is and how it thinks. Let’s grab our mental LEGO set and start building!
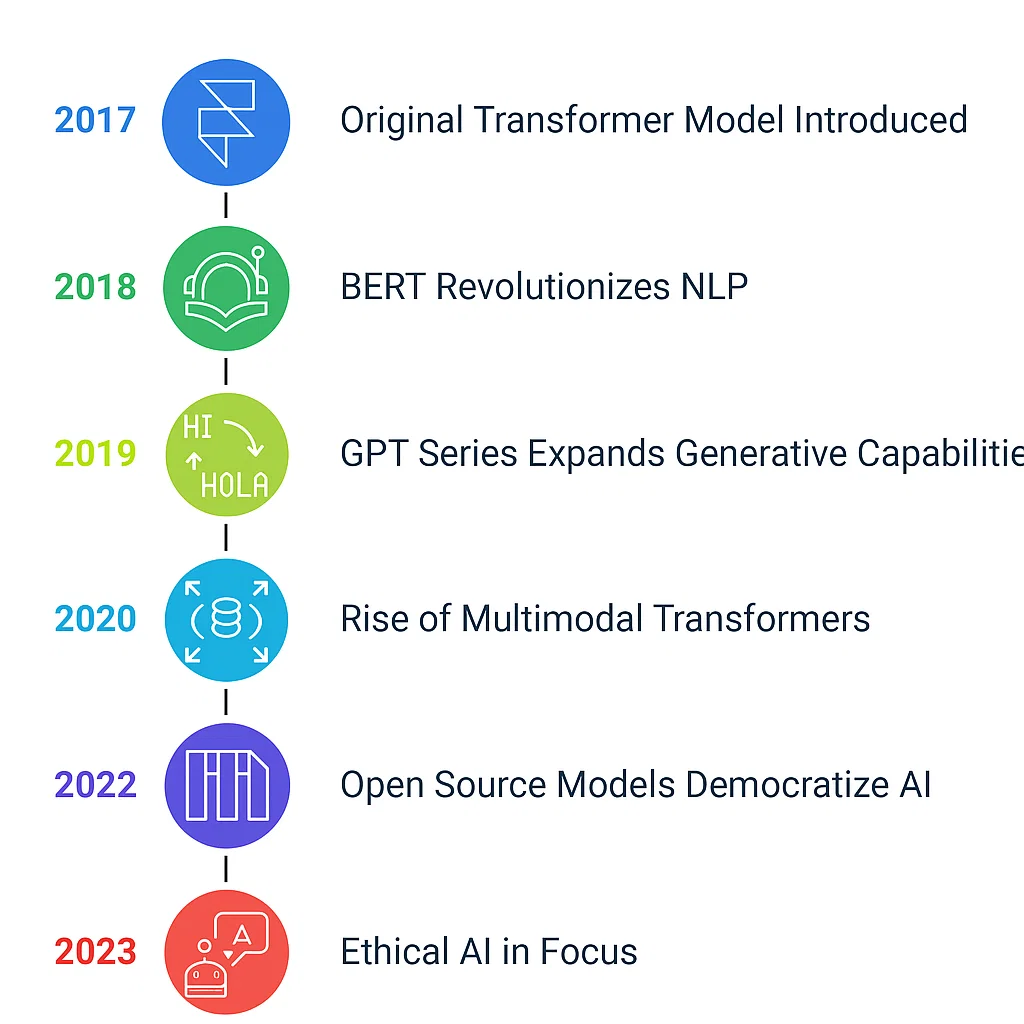
The Road to Transformers: A Historical Context
To appreciate transformers, we need to understand the challenges they solved. Like smartphones evolving from clunky cell phones, transformers are the sleek descendants of earlier AI models.
The Pre-Transformer Era
1. RNNs (Recurrent Neural Networks) – The Tape Recorders of AI
RNNs handled sequences like sentences or time-series data by retaining memory of previous inputs, but they had limitations:
Long-term memory issues: Struggled to recall earlier parts of long sequences.
Slow training: Sequential processing was time-consuming.
Performance degradation: Longer sequences led to diminishing returns.
Example: Imagine reading a novel but forgetting Chapter 1 by Chapter 10. That’s how RNNs handled long texts.
2. LSTMs (Long Short-Term Memory) – A Memory Upgrade
LSTMs improved RNNs by selectively remembering key information, excelling in tasks like speech recognition and translation. Yet, they had drawbacks:
Complex and slow to train.
Limited handling of very long contexts.
Sequential processing bottlenecks.
Example: LSTMs were like using sticky notes for a 1,000-page book better than nothing, but far from perfect.
3. The Bottleneck That Sparked Change
Older models processed data one word at a time, leading to:
Slow performance.
Limited parallelism.
Context loss in long inputs.
This prompted: What if we could process everything simultaneously, focusing on what matters most?
The Paradigm Shift
Transformers marked a revolutionary change by:
Moving from sequential to parallel processing.
Replacing local memory with global attention.
Enabling fast, deep learning at scale.
Example: It’s like upgrading from reading a book line by line to grasping the entire narrative instantly. This shift culminated in the 2017 paper, “Attention Is All You Need,” introducing the transformer model.
Breaking Down Transformers: The LEGO Blocks of AI
Transformer models seem complex but are a stack of reusable components, like LEGO bricks, each with a distinct role. Let’s explore the core pieces.
The Transformer Blueprint
A transformer consists of two primary parts:
Encoder: Reads and interprets the input.
Decoder: Generates output based on the encoder’s understanding.
For translation, the encoder processes input (e.g., English), and the decoder produces output (e.g., French). Models like BERT use only encoders, while GPT relies on decoders.
Core Components
1. Input Embedding
Words are converted into numerical vectors capturing meaning based on context, frequency, and position.
Example: Each word gets a unique barcode encoding its meaning, mood, and grammatical role.
2. Positional Encoding
Since transformers process words in parallel, positional encoding adds signals to indicate word order.
Example: In “The cat chased the mouse” vs. “The mouse chased the cat,” positional encoding clarifies who’s chasing whom.
3. Self-Attention Mechanism
Self-attention, the heart of transformers, weighs the importance of each word relative to others in a sentence. How It Works:
Each word is assigned scores for its relationships with others.
Scores dynamically adjust the word’s meaning based on context.
Example: In “She poured water into the glass because it was empty,” self-attention determines “it” refers to the glass, not the water.
4. Multi-Head Attention
Multiple attention heads analyze different aspects of a sentence, like syntax, sentiment, or relationships.
Example: Like friends analyzing a painting one notices colors, another emotions, another composition yielding a richer understanding.
5. Feedforward Neural Network
After attention, a feedforward network refines data with nonlinear transformations, adding depth.
Example: Like polishing a LEGO structure to ensure it’s sturdy and refined.
6. Layer Normalization and Residual Connections
To maintain stability:
Residual connections preserve information by skipping layers.
Layer normalization ensures consistent data flow.
Example: Like checking a LEGO tower’s alignment to prevent toppling as it grows taller.
The Transformer Flow
Each encoder or decoder block follows:
Input Embedding + Positional Encoding
Multi-Head Self-Attention
Add & Normalize
Feedforward Layer
Add & Normalize
Blocks are stacked (6–12 layers) for a deep, powerful model.
The Power of Attention: Why Transformers “Understand”
The attention mechanism is the crown jewel, enabling nuanced, contextual understanding. Let’s explore its power.
What Is Attention?
Attention focuses on relevant input parts while ignoring noise.
Example: At a noisy party, hearing your name makes you tune out everything else. Attention zeros in on key words.
Self-Attention: Conversations Within a Sentence
Self-attention evaluates relationships between all words simultaneously, adjusting meanings dynamically. How It Works:
Each word transforms into:
Query (Q): What am I looking for?
Key (K): Do I match what’s asked?
Value (V): What information do I carry?
Example: In “The bank raised interest rates,” self-attention clarifies “bank” as a financial institution, based on “interest” and “rates.”
Why Multi-Head Attention Excels
Multiple heads analyze a sentence from perspectives like grammar, tone, or relationships, creating a holistic understanding.
Example: Like rewatching a movie to catch plot, emotions, and foreshadowing each pass reveals new insights.
Attention Scores: A Window Into the Model’s Mind
Attention scores are interpretable, showing prioritized words.
Example: In “The trophy doesn’t fit into the suitcase because it’s too small,” attention maps show “it” refers to the suitcase, aiding debugging and trust.
Why Attention Outshines Older Methods
Compared to RNNs (slow, forgetful) and CNNs (clunky for language), transformers offer:
Parallel processing for speed.
Long-range dependency capture for context.
Scalability for massive datasets.
Example: Like upgrading from walkie-talkies (RNNs) to a Zoom call (transformers), where everyone communicates simultaneously.
Real-World Applications: Transformers in Action
Transformers power daily tools, from chatbots to image recognition. Here’s how they transform industries.
Natural Language Processing (NLP)
Transformers redefine language processing:
ChatGPT and Bard: Human-like conversations.
Grammarly: Contextual writing suggestions.
Google Translate: Accurate translations.
Example: Saying, “Remind me to call Mom tomorrow,” a transformer-powered assistant sets the reminder by understanding intent.
Vision Transformers (ViT)
Transformers excel in vision by treating image patches like words:
Facial recognition.
Object detection in autonomous vehicles.
Medical diagnostics for early cancer detection.
Example: ViT systems help hospitals detect cancer in X-rays faster than radiologists.
Audio and Speech
Transformers enhance audio processing:
Whisper by OpenAI: Transcribes audio across languages and accents.
Alexa and Siri: Understand complex voice commands.
Example: Correcting mid-sentence (“Set a timer for fifteen no, five minutes”), transformers ensure accuracy.
Multimodal Models
Transformers process text, images, and audio simultaneously:
GPT-4 with Vision: Describes images, reads charts.
DALL·E: Generates images from text.
CLIP: Links text and images.
Example: An AI explaining a report’s charts while reading aloud uses multimodal transformers.
Enterprise and Research
Finance: Fraud detection, trading insights.
Healthcare: Patient record analysis, research synthesis.
Legal: Contract summarization, case prediction.
Example: Law firms summarize hundreds of legal pages in minutes, saving hours.
Building Your Own Transformer: A Beginner’s Roadmap
Ready to build a transformer? A mini-transformer is achievable and educational.
Step 1: Understand the Core Blocks
Grasp:
Embedding Layer: Words to vectors.
Positional Encoding: Tracks order.
Multi-Head Attention: Focuses on relationships.
Feedforward Network: Refines data.
Layer Normalization & Residuals: Ensures stability.
Analogy: Don’t build a LEGO set without instructions. Learn how pieces fit.
Step 2: Choose the Right Tools
Use:
Hugging Face Transformers: Prebuilt models, APIs.
PyTorch or TensorFlow: Lower-level control.
KerasNLP or Simple Transformers: Simplified abstractions.
Tip: Fine-tune a model like BERT on a small dataset, like movie reviews.
Example: A junior developer built a sentiment analysis bot in two weeks, used by an e-commerce store.
Step 3: Train Smart
Transformers are resource-intensive, but:
Use Google Colab for free GPUs.
Train on small datasets (1,000–5,000 entries).
Leverage transfer learning with pretrained models.
Example: A student used DistilBERT on Colab for a fake-news classifier.
Step 4: Evaluate and Iterate
Test:
Use validation sets to prevent overfitting.
Track accuracy, F1 score, loss.
Visualize with confusion matrices, attention heatmaps.
Analogy: Like checking a rocket’s trajectory before launch, evaluate before deployment.
Step 5: Deploy or Integrate
Make it useful:
Deploy with Streamlit or Flask as a web app.
Integrate with tools like Slack, dashboards.
Export as an API endpoint.
Example: A hobbyist deployed a resume-screening AI, used by startups.
Pro Tip: Learn by Experimenting
Tweak parameters, reduce layers, visualize attention heads. Breaking and fixing teaches more than textbooks.
The Future of Transformers
The transformer story continues to evolve.
Efficient Transformers
Research focuses on smaller, faster models:
DistilBERT, TinyBERT: Lightweight versions.
LoRA: Fine-tunes with fewer parameters.
Quantization & Pruning: Mobile deployment.
Example: A healthcare startup used TinyBERT on edge devices for rural clinics.
Example: A media company auto-generated video captions, cutting manual work by 60%.
Open-Source Revolution
Open-source models like Mistral, LLaMA 2, Falcon, Phi-2 democratize AI.
Example: An indie game developer used LLaMA 2 for dynamic NPC dialogue.
Ethical Transformers
Future transformers prioritize:
Bias mitigation.
Hallucination reduction.
Fairness across languages, cultures.
Example: A fintech startup improved trust by addressing biases in recommendations.
Conclusion
Transformers are the LEGO bricks of modern AI, enabling nuanced understanding and generation across language, images, and more. By exploring their components, applications, and building your own, you can join the AI revolution. The future is bright, efficient, and multimodal start building today!