The Magic of Attention Mechanisms in Language Models
The Spotlight Effect: How AI Zeroes in on What Matters
The Magic of Attention Mechanisms in Language Models
Introduction: From Clueless to Laser-Focused – The AI Transformation
Imagine you’re reading a book, and your brain is automatically highlighting the words that matter most to understand the story. That’s exactly what attention mechanisms do for AI.
Back in the day, early language models processed every word with equal importance. That’s like trying to understand a movie by giving equal screen time to background extras and the main character—not very smart, right?
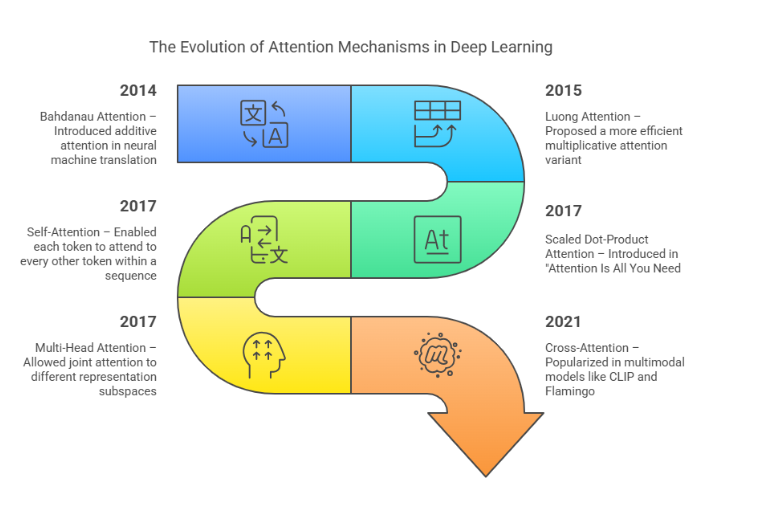
Then came the game-changer: attention. Introduced with the paper “Attention is All You Need” in 2017, attention mechanisms reshaped how models like GPT and BERT “read” text. Now, instead of treating all words equally, models can focus—like a flashlight—on the parts of text that actually matter for the task at hand.
In this blog, we’ll:
Break down how attention works (without the jargon overload)
Use real-life analogies to make sense of technical concepts
Walk through how this affects AI tasks like translation, question-answering, and even chatbots
Whether you’re an AI newbie or someone who's heard the term “self-attention” tossed around, you’re in the right place. Let’s decode the magic behind the spotlight effect in AI.
What Is Attention in Language Models?
A Simple Analogy: The Party Conversation Trick
Let’s say you’re at a noisy party, trying to talk to your friend. There are dozens of conversations happening around you, music in the background, maybe someone clinking glasses. Yet somehow, your brain filters out the noise and lets you focus on your friend’s voice.
That, in a nutshell, is what attention does for language models.
So, What Does It Actually Do?
In technical terms, attention allows a model to assign weights to different words in an input sequence based on how relevant they are to understanding a specific word or task.
Instead of processing a sentence like this:
"The cat sat on the mat because it was tired."
…and guessing whether “it” refers to the cat or the mat (classic NLP problem!), attention mechanisms help the model zero in on “cat” as the relevant reference.
Real-Life Example: Predictive Text
You’re typing “Can you send me the...” and your keyboard suggests “file” or “document.” How does it guess? The model uses attention to look back at each word and figure out which ones are important for predicting the next one. In this case, “send” and “me” get more attention than “the.”
Here’s what’s happening under the hood (don’t worry, we’ll simplify it in the next section):
The model encodes each word into a vector (a mathematical representation).
Then it calculates how much each word should “attend to” every other word.
The result? A smarter model that knows what to focus on.
How Does Attention Actually Work? (A Beginner-Friendly Breakdown)
Think of It Like a Weighted Group Chat
Imagine you’re in a group chat with five friends. You ask, “What movie should we watch tonight?” Not all replies matter equally:
One friend sends a relevant suggestion: “Let’s watch Inception.”
Another drops a meme: “Minions forever.”
One goes silent.
One says, “Anything but horror.”
Another suggests: “Inception sounds good.”
You naturally give more weight to the useful responses—like “Inception”—and ignore the distractions. That’s exactly what attention mechanisms do in a sentence.
The Core Ingredients of Attention:
Let’s keep it simple. Every word gets transformed into three vectors:
Query (Q) – What am I looking for?
Key (K) – What do I have to offer?
Value (V) – What information do I bring?
Here’s how it flows:
Compare Query and Key – Determines how relevant one word is to another.
Calculate a Score – Higher means more relevant.
Multiply by Value – Take only the useful info based on relevance.
Sum it up – Combine all this to produce a new context-aware word representation.
Example:
In the sentence “The bank will not lend money to the poor,” the model needs to figure out that “bank” means a financial institution—not a riverbank. Attention helps it pick up on clues like “lend” and “money” to choose the right meaning.
Why This Is Cool (Even If You're Not a Math Nerd):
It's dynamic: The model adjusts focus differently depending on the task or sentence.
It handles context better: Especially long-distance relationships between words.
It's efficient: It replaces the need for scanning everything in order (like RNNs did).
4. Types of Attention: Self-Attention vs Cross-Attention (and Why They Matter)
Self-Attention: Talking to Yourself, But Smarter
In self-attention, every word in a sentence looks at every other word (including itself) to figure out which ones matter.
Let’s say your sentence is:
“She saw a dog in the park and it barked loudly.”
When processing the word “it,” the model uses self-attention to scan the whole sentence and say, “Hmm, what does ‘it’ refer to? Oh! Probably ‘dog.’” It doesn’t just look at nearby words—it evaluates everything in context.
Real-life example:
When you’re chatting with a smart assistant like Siri or Alexa, and you say, “Remind me to call mom when I reach home,” the model uses self-attention to:
Understand that “me” is you,
“Mom” is a person (not your friend’s mom),
And “home” refers to your personal location.
It’s pulling together all the info in one go—magic!
Cross-Attention: Bringing in External Help
Now imagine you're translating a sentence from English to French.
In cross-attention, the decoder (the part generating the French translation) looks at the encoder’s output (which processed the English input) to understand what it should be paying attention to.
This is where models like Transformers shine. They use:
Self-attention in both encoder and decoder layers,
Cross-attention specifically in decoder layers to fuse input and output meanings.
Real-life example:
Google Translate uses cross-attention when converting:
“The president addressed the nation last night.”
It ensures that "president" gets mapped correctly, even if "addressed" and "nation" are far apart in the translated sentence’s structure. This precision comes from cross-attention syncing both languages.
Quick Recap:
Self-Attention → Looks inward → Helps understand each word in context of all other words.
Cross-Attention → Looks outward → Helps align input and output sequences (used in translation, image captioning, etc.).
Why Transformers Took Over: The Attention Revolution
Out with the Old: The RNN Bottleneck
Before Transformers, language models relied on Recurrent Neural Networks (RNNs) and LSTMs. These models processed data sequentially—one word at a time.
Sounds fine, right? But here’s the kicker:
They struggled with long sentences.
If the crucial info was at the beginning of a sentence, by the time the model reached the end, it would kind of… forget.
Real-life example:
If you're reading a long legal email and someone asks you what the first clause said, you might go, “Uh… I already scrolled past it.” RNNs had the same problem.
Enter Transformers: Parallel and Powerful
Transformers, powered by attention mechanisms, came in and said, “Why read sequentially when we can read everything at once?”
Thanks to self-attention, Transformers:
Process all words simultaneously (parallel processing),
Learn long-range dependencies way better,
Are massively faster to train and scale.
This shift was a total game-changer.
Real-life example:
Imagine having a team of interns read an entire document together and highlight all important parts at once, instead of one person reading line by line. That’s the Transformer approach!
The Real Revolution: Scaling with Attention
With attention at the core, Transformers led to groundbreaking models:
BERT (for understanding language),
GPT (for generating text),
T5, XLNet, RoBERTa, and more.
They’re all Transformer-based and capable of:
Summarizing emails,
Translating websites,
Generating code,
Even writing blogs like this one.
Key Takeaways:
RNNs walked so Transformers could fly.
Transformers ditch the sequential limitation.
Attention allows scaling to billion-parameter models with context awareness.
How Multi-Head Attention Works: Like Multitasking for the Brain
What is Multi-Head Attention?
Let’s say you're analyzing a sentence. You might want to focus on:
Who is doing the action,
What the action is,
And where it’s happening.
Now imagine doing all of that at the same time—that’s what multi-head attention enables.
In simple terms:
Instead of looking at just one “type” of relationship between words, the model uses multiple attention heads, each focusing on a different pattern or connection in the sentence.
Breaking It Down: The Heads Behind the Magic
Each head:
Runs its own attention mechanism.
Picks up different contextual clues (e.g., subject-verb, object modifiers, long-range dependencies).
Outputs a slightly different representation of the same sentence.
Then, all the heads are combined (concatenated and projected) into one powerful, nuanced understanding.
Real-life example:
Imagine a group of detectives watching the same crime scene footage.
One focuses on body language,
Another on facial expressions,
A third on timestamps.
They each bring their unique insights, which when combined, solve the case faster and better. That’s multi-head attention.
Why It Matters: The Edge in Understanding
This is what lets models like GPT:
Understand the tone of a sentence (sarcasm? excitement?),
Track entities in a story over many paragraphs,
Know that “Apple” in one context is a fruit, and in another, a tech giant
Quick Recap:
Multi-head attention = multiple perspectives at once.
Improves accuracy, nuance, and comprehension.
Essential for deep understanding in modern LLMs.
Positional Encoding: Giving Words a Sense of Order
The Transformer’s Problem: No Memory of Sequence
Transformers, as powerful as they are, come with one weird quirk:
They process words all at once—which means they don’t naturally know the order of words.
But in language, order is everything:
“The dog chased the cat” ≠ “The cat chased the dog”
So how do Transformers handle this?
The Fix: Positional Encoding to the Rescue
To inject a sense of order, Transformers add positional encodings to each word’s vector. This gives the model an idea of where each word appears in a sentence.
There are a couple of ways to do this:
Sinusoidal encoding (mathy but efficient),
Learned encoding (learns position info during training).
Think of it like tagging each word with a GPS pin 📍 showing where it is in the sentence.
Real-life example:
Imagine reading a story where the pages are shuffled randomly. You’d be totally lost. But if each page had a page number, you could reassemble the story in the right order.
That’s exactly what positional encoding does—it puts the words back in the right place.
Why This Matters: Context Isn’t Just About Words
Without order, the model might:
Mix up subject and object,
Misunderstand timelines,
Lose meaning entirely.
With positional encoding:
Sentences retain flow,
Narratives make sense,
The model understands not just what is said, but how it’s structured.
Transformers need positional cues to understand order.
Positional encoding helps maintain sentence structure and meaning.
It’s subtle, but critical to the model’s performance.
Putting It All Together: A Day in the Life of a Language Model
From Input to Output: The Full Attention Workflow
Now that we’ve covered attention, multi-head magic, and positional encoding, it’s time to walk through how a language model like GPT actually thinks—step by step.
Let’s say you type:
“Can you book a table for two at the Italian place tomorrow night?”
Here’s how the model processes it:
Tokenization:
The sentence is broken down into word pieces or "tokens."
Embedding + Position:
Each token is converted into a vector + gets its positional encoding.
Self-Attention + Multi-Head Attention:
The model looks at how each word relates to every other word—across multiple heads.
Layer Stacking:
This process happens across many transformer layers, each refining the output.
Prediction & Output:
Finally, the model predicts the next word or generates a complete response.
Real-life example:
Think of it like a chef reading a recipe while prepping a dish:
Reads all the ingredients (tokens),
Understands which steps depend on which (attention),
Pays attention to the order of cooking (positional encoding),
Puts everything together into a perfect meal (output generation).
That’s how GPT serves up your answers
Why This Is Powerful for Developers and Users Alike
Understanding this workflow helps you:
Fine-tune your own models more effectively,
Debug weird outputs (why did it say that?),
Appreciate the complexity behind each AI-generated word.
A Transformer model combines all the attention tricks + order awareness to generate meaningful language.
It’s like running a full orchestra—multiple players, synchronized beautifully.
Why Attention Outperforms Traditional Methods
Before Transformers took the stage, we had RNNs and CNNs doing the heavy lifting for NLP tasks. They walked so attention could fly—but once attention arrived, it was game over in many ways.
RNNs (Recurrent Neural Networks): The Overworked Memory
RNNs process input sequentially, word by word, kind of like reading a book through a tiny magnifying glass. They have trouble remembering stuff from earlier in the sentence, especially in long sequences.
Problem:
Vanishing gradients, memory limitations, and slow processing.
Example:
“The man who wore a blue jacket and carried a guitar walked into the bar.”
If you’re using an RNN, by the time you get to “walked into the bar,” the model might’ve forgotten the “man” at the beginning. Not ideal.
CNNs (Convolutional Neural Networks): Great at Vision, Not So Much at Language
CNNs were adapted for NLP because they’re good at finding patterns—like in image pixels. But they lack a sense of sequence. Language is all about order and relationships. CNNs don’t naturally “know” that the word “not” flips the meaning of a sentence.
Example:
"The food was not good."
CNNs might treat “good” as positive and miss the “not.” That’s a major oops.
Attention to the Rescue
Now compare that with attention-based models:
They look at all parts of a sentence simultaneously (no forgetting the start).
They weigh relationships between words (understand nuance).
They process inputs in parallel (way faster).
They’re modular—easy to scale and fine-tune.
Real-life metaphor:
Imagine three detectives reading a letter:
RNN detective: Reads line by line, forgets parts halfway through.
CNN detective: Looks at chunks, spots keywords, but misses the context.
Attention detective: Scans the entire letter at once, connects the dots, and instantly understands who did it.
That’s why attention mechanisms revolutionized NLP and became the foundation of models like BERT, GPT, and more.
Real-World Applications: Where Attention Truly Shines
So, attention mechanisms sound cool in theory, but where do they actually show up in the stuff we use every day?
1. Smart Assistants That Actually Sound Smart
Siri, Alexa, Google Assistant—these tools rely on attention-powered models to understand what you're asking, even if your sentence is long or messy.
Example:
You say:
“Hey Google, can you remind me to call mom after I pick up the dry cleaning but before I head to the gym?”
That’s a multi-step command. Thanks to attention mechanisms, the AI can pick out key entities, understand the sequence, and respond intelligently—rather than getting overwhelmed or missing important details.
2. Text Summarization & Paraphrasing
Ever used tools like Grammarly or QuillBot? Behind the scenes, attention mechanisms are powering their understanding of sentence structure and meaning.
Example:
Original:
“Due to unforeseen circumstances, the meeting has been postponed.”
Paraphrased with attention:
“The meeting was delayed because of unexpected events.”
Same meaning, different wording—handled smoothly by attention-driven models.
3. Real-Time Language Translation
Google Translate and DeepL have leveled up massively since moving from phrase-based to attention-based translation.
Example:
Translating:
“I’m feeling under the weather.”
An attention model can infer that it’s an idiom and not about actual weather, producing the correct equivalent in another language like “Je ne me sens pas bien” in French (meaning “I don’t feel well”).
4. Document Search & Question Answering
Systems like ChatGPT, BERT-powered search engines, or even customer support bots can now understand questions contextually—instead of keyword matching.
Example:
Ask: “What’s the refund policy if I return a product after 30 days?”
An attention model can scan through a huge document and focus on just the relevant sections to provide a spot-on answer.
5. Chatbots & Conversational AI
Attention is why modern chatbots don’t just echo back weird answers—they follow the flow of a conversation and respond coherently.
Example:
User: “Do you sell shoes?”
Bot: “Yes, we do! Any particular style you’re looking for?”
User: “Something casual.”
Bot: “Got it. How about sneakers or loafers?”
This smooth back-and-forth would be impossible without attention tracking conversation history.
Challenges & Limitations: The Not-So-Magical Side of Attention
While attention mechanisms have revolutionized language models, they’re not all stardust and unicorns. There are real challenges—technical, practical, and even ethical—that still need addressing.
1. Memory Isn’t Infinite
Even though attention allows models to “focus,” it doesn’t mean they can remember everything forever.
Most models have a context window (like 2,000 to 100,000 tokens depending on the model), beyond which older information gets “forgotten.”
That’s why sometimes a long document confuses the model—or you find yourself repeating things to a chatbot.
Real-life analogy:
Imagine trying to have a detailed conversation while only being allowed to remember the last few sentences. That’s the current reality for many models.
2. High Computational Cost
Attention isn’t cheap. In fact, it's quadratic in complexity with respect to sequence length. Meaning:
Processing a sequence twice as long requires four times the computation.
That’s tough on hardware and limits model speed, especially in real-time applications.
Example:
This is why models like GPT-4 Turbo use smarter attention optimizations (like "sparse attention") to keep things fast without losing too much accuracy.
3. Bias Amplification
Attention mechanisms learn from data. If that data has bias, the model might focus on and even amplify those biases.
Example:
If a model reads thousands of job listings where leadership roles are mostly associated with men, it may (unintentionally) highlight male-related terms more when generating content about CEOs.
4. Interpretation Is Still Tricky
Just because a model attends to a word doesn’t always mean it understands it the way humans do.
Researchers are still trying to interpret what exactly attention scores mean.
Some attention heads attend to weird, non-intuitive things—almost like a black box.
Fun fact:
In some studies, models placed attention on random punctuation marks or filler words… and still got the right answer!
The Future of Attention: What's Next?
The attention mechanism has come a long way—but it’s still evolving. Researchers and engineers are constantly working to improve how models “pay attention” to what matters most, while balancing speed, accuracy, and interpretability.
1. Longer Context Windows = Smarter Conversations
We're already seeing language models like GPT-4 Turbo and Claude handling up to 100,000+ tokens. That’s like remembering the entire content of a short novel.
This opens doors to deep document analysis, long conversations, multi-turn reasoning, and even better memory across tasks.
Expect models that can handle entire meetings, research papers, or books without breaking a sweat.
Real-life example:
Imagine a legal assistant AI that can read a 200-page contract and give insights without needing you to split it into parts. That’s where we’re headed.
2. Sparse and Efficient Attention
Researchers are exploring sparse attention, linear attention, and routing mechanisms to reduce the computation load.
These techniques help models focus only on relevant parts, skipping unnecessary computations.
It makes real-time deployment feasible on smaller devices (yes, even phones!).
Fun mention:
Google’s BigBird, Reformer, and Longformer are models trying to scale attention without melting GPUs.
3. Hybrid Models: Attention + Memory
Some models are beginning to combine attention mechanisms with external memory banks or retrieval systems.
Instead of remembering everything, they “look up” information when needed—like a built-in search engine.
This means smaller, faster models with access to much larger knowledge bases.
Real-world vibe:
Think of it like having a brilliant intern who doesn’t memorize everything but knows exactly where to find it instantly.
4. Multimodal Attention
Attention isn’t just for text anymore.
It’s now being used in vision, audio, video, and even robotics.
Models like GPT-4 and Gemini handle images and text with the same underlying mechanisms.
Example:
You upload an image of your messy pantry, and your AI suggests recipes based on what it sees—thanks to attention across vision + text.
5. Ethical Attention
The future isn’t just smarter—it’s also more accountable.
Researchers are pushing for interpretable and auditable attention models to tackle bias and misinformation.
Expect more transparency tools to help users understand what the AI focused on—and why.
Final Thoughts: Why Attention Is the Real MVP of AI
When you peel back the layers of what makes modern AI so astonishing—be it generating poetry, writing code, analyzing images, or chatting like a human—it almost always comes back to one thing: attention.
Just like in life, what we choose to focus on defines what we understand, remember, and act on. Attention mechanisms let AI do the same. They’ve become the foundation of how machines learn to prioritize meaning in oceans of data.
Let’s not forget:
Without attention, transformers wouldn’t exist.
Without transformers, we wouldn't have ChatGPT, BERT, Gemini, or Claude.
And without those? Well, AI would still be stumbling over basic grammar.
The beauty is in the elegance—a simple concept inspired by how humans think became the engine behind the most powerful tech of our time.
So next time your AI assistant responds like it “gets you,” just know—it’s all thanks to attention.