Text Clustering: Grouping Similar Documents Automatically
Document Speed Dating: How AI Finds Text SoulmatesText Clustering: Grouping Similar Documents Automatically
The Problem with Information OverloadWhy Your Digital Documents Need Soulmates Too
Imagine you’re a content manager at a rapidly growing startup. Every week, your inbox floods with thousands of emails, meeting notes, survey responses, and feedback forms. Your team is expected to find patterns in all this unstructured text—and fast. But as you scroll through yet another batch of product reviews or customer support tickets, it starts to feel like you're searching for a needle in a haystack.
That’s the reality of the modern workplace. We're swimming—no, drowning—in text. Emails, chat messages, research papers, blog posts, and customer feedback have become endless rivers of unstructured information. Traditional methods of organizing documents (like tagging or manual sorting) just don’t scale.
Here’s the kicker: hidden in all this mess are meaningful insights. A cluster of customer complaints about a feature, recurring praise about a new update, or emerging trends in academic research—all of it gets lost unless we group similar documents together.
And that’s where AI steps in.
Text clustering is like speed dating for documents. It allows us to pair similar texts automatically—no prior labels, no tedious manual work—just pure, pattern-driven matchmaking.
Real-Life Chaos: A Day in a Content Manager’s Life
Let’s get real with an example.
Meet Sara, a content strategist at a fast-paced e-commerce company. After launching a new product line, her team received over 7,000 customer reviews in just a month. She wanted to know what users were loving—or hating—without reading every single one.
Without clustering:
She’d have to manually read and categorize thousands of reviews.
She might miss recurring but subtle complaints.
Valuable time would be wasted on sorting instead of solving.
With text clustering:
The reviews are grouped into natural clusters (e.g., “delivery delays”, “packaging complaints”, “great product quality”).
Sara immediately identifies pain points and product highlights.
Her team makes data-driven decisions faster.
Clustering isn't just about saving time—it’s about uncovering patterns you didn’t even know were there.
Enter Text Clustering – The AI MatchmakerWhat Is Text Clustering, Really?
At its core, text clustering is an unsupervised machine learning technique that groups together documents with similar content. No human labeling, no predefined categories—just the algorithm working its magic to find hidden relationships in text.
Think of it like a cocktail party. You’ve got a room full of strangers. Some are chatting about tech, others about cooking, a few about travel. Without being told who belongs to which group, you can overhear conversations and naturally sense who fits together.
That’s exactly what clustering does with documents. It listens, picks up patterns, and gently nudges similar pieces of text into the same group.
How It Works (Without Going Full Nerd)
Here’s a simplified step-by-step breakdown of what goes on behind the scenes:
Text Preprocessing
Remove noise (punctuation, special characters, etc.)
Convert everything to lowercase
Tokenize text (split into words or phrases)
Remove stop words (like “the”, “is”, “and”)
Optional: Use stemming or lemmatization to simplify words
Feed those numerical vectors into clustering models like:
K-Means (the classic)
DBSCAN (great for irregular clusters)
Hierarchical Clustering (great for visual trees)
HDBSCAN (smart enough to find clusters of varying sizes)
Result: Clusters of Similar Documents
Each group represents a unique topic or theme
You get a birds-eye view of what’s going on in your text data
A Real-World Example: Customer Support Ticketing SystemCompany: A SaaS company with thousands of monthly support requests.
Problem: The support team couldn’t keep up. Tickets ranged from feature requests to bug reports and general inquiries—all mixed up with no clear categories.
Solution: They implemented text clustering using TF-IDF and K-Means.
Outcome:
Clusters like “Password Reset Issues”, “Billing Questions”, and “Feature Requests” naturally emerged.
Tickets were auto-tagged based on cluster membership.
Response times improved by 45% within two weeks.
Text clustering transformed chaos into clarity—without a single manually written rule.
Under the Hood: Algorithms That Make the Magic HappenK-Means: The Reliable First Date
K-Means is the go-to algorithm when you want quick, effective clustering. It's like the dependable friend who always shows up on time and gets the job done
How it works:
You tell it how many clusters you want (say, 5).
It randomly picks 5 points (centroids) and assigns documents based on closeness.
Then it adjusts those points until everything fits neatly.
Best for: Clean datasets with relatively equal-sized clusters.
Real-life use case:
A marketing agency clustered thousands of ad copies using K-Means. They found that certain language styles were more effective for certain demographics, helping them tailor future campaigns for higher engagement.
DBSCAN: The Free Spirit Who Doesn’t Need Rules
Unlike K-Means, DBSCAN doesn’t need you to define the number of clusters. It looks at density—how close documents are to each other—and lets patterns emerge naturally.
Why it’s cool:
Handles noise (outliers) gracefully
Detects irregularly shaped clusters
Best for: Datasets where clusters aren’t well-defined or evenly spread.
Real-life use case:
An online retailer used DBSCAN to analyze product reviews. DBSCAN uncovered a small but vocal group of users reporting a rare product defect—something K-Means had missed. This early insight prevented a potential recall disaster.
Hierarchical Clustering: The Family Tree Approach
Hierarchical clustering builds a tree of documents. You don’t need to specify cluster counts ahead of time—you can slice the tree at any level of granularity.
Types:
Agglomerative (bottom-up): Start with individual docs, merge them up
Divisive (top-down): Start with everything, split down
Best for: When you want a visual or layered understanding of your document relationships.
Real-life use case:
A legal firm used hierarchical clustering on case documents. They could trace how certain legal arguments evolved across years—like a genealogy of legal thought.
HDBSCAN: The Smartest Matchmaker in the Room
HDBSCAN combines the best of DBSCAN and hierarchical clustering. It’s density-based, doesn’t need a cluster count, and adapts beautifully to real-world messiness.
Why it shines:
Finds clusters of varying sizes
Robust to noise
Produces meaningful labels (even when others fail)
Real-life use case:
A media analytics company used HDBSCAN to cluster social media posts. It helped them isolate small but powerful trends (like early mentions of a viral hashtag) weeks before they hit mainstream.
Each of these algorithms brings a different flavor to the clustering process—pick based on the nature of your text and what kind of soulmates you're looking to match.
When Clustering Goes Wrong: Common Pitfalls and How to Dodge Them
Even AI matchmakers can misread the room. Clustering might seem magical when it works, but when it doesn’t, the results can be hilariously—or disastrously—off. Here are the most common missteps and how to avoid them.
1. Garbage In, Garbage Out: Poor Preprocessing
Clustering only works as well as the data it's fed. If your text is noisy, unclean, or inconsistent, your clusters will reflect that chaos.
What to watch for:
Stop words (like “the”, “is”, “and”) cluttering the signal
Inconsistent casing or punctuation
Words with different forms (e.g., “run” vs. “running”)
How to fix it:
Normalize your text (lowercasing, stemming or lemmatizing)
Remove stop words
Consider TF-IDF or Word Embeddings instead of raw counts
Real-life example:
A news aggregator clustered articles without removing boilerplate headers (like “Subscribe Now!”). This led to wildly incorrect groups. Once the text was cleaned properly, clustering accuracy jumped over 30%.
2. Wrong Algorithm, Wrong Crowd
Using the wrong clustering algorithm is like bringing a poet to a tech conference. Some algorithms assume neat, spherical clusters (like K-Means), while others embrace messy, uneven groupings (like DBSCAN or HDBSCAN).
How to choose:
K-Means: Great for clean, large datasets with clear cluster boundaries
DBSCAN/HDBSCAN: Better for uneven, noisy datasets
Hierarchical: Useful when the number of clusters is unknown or layered
Real-life example:
A startup tried K-Means on customer support tickets. The clusters were meaningless because complaints were highly variable. Switching to HDBSCAN revealed distinct issue categories and improved ticket routing efficiency.
3. Choosing the “Right” Number of Clusters (Or Not Having To)
K-Means requires you to predefine the number of clusters, but how do you know what the right number is?
Solutions:
Use the Elbow Method or Silhouette Score to find optimal cluster count
Prefer DBSCAN or HDBSCAN if you don’t want to guess
Real-life example:
A content manager used 3 clusters arbitrarily and missed the nuance in article types. Using the elbow method revealed 7 natural groupings, which made internal categorization much more intuitive.
4. Overfitting: Making It Too Perfect
Sometimes, clustering results look amazing—but only because they’re tuned too closely to a specific dataset.
Symptoms:
Works great on one batch but fails on new documents
Too many tiny clusters that don’t generalize
Prevention tips:
Test your clustering on multiple datasets
Use cross-validation where possible
Keep cluster interpretation broad enough to be useful
Real-life example:
An HR firm clustered employee reviews and got clusters like “loves coffee,” which, while cute, weren’t actionable. Reworking the clustering with a broader lens revealed categories like “management satisfaction” and “work-life balance.”
5. Ignoring the Human Touch
No matter how smart the algorithm, interpretation still needs human oversight. Clusters don’t mean anything if you can’t explain or act on them.
Checklist:
Can you name or describe each cluster?
Do the documents in each cluster make sense together?
Would a non-technical stakeholder understand the output?
Real-life example:
A bank used clustering to analyze customer complaints. The AI grouped some complaints correctly—but labeled one cluster “?” because the team didn’t review it. It turned out to be a pattern of ATM fraud—missed entirely because no one interpreted the result.
Clustering is powerful, but like any relationship advice—context, effort, and interpretation matter. Know the tools, clean the data, and always keep humans in the loop.
Cluster Love in Action: Real-World Use Cases of Text Clustering
Text clustering isn’t just a fancy data science trick—it’s already transforming how businesses and platforms operate across industries. Here are some compelling real-world examples of how organizations use clustering to solve problems, save time, and even discover new opportunities.
1. News Aggregators: Organizing the Chaos
News platforms like Google News use clustering to group articles on the same story from different sources. This helps readers see multiple perspectives and follow evolving events without getting overwhelmed.
How it works:
Articles are vectorized and clustered in near real-time
Clusters dynamically update as stories develop
Result:
Readers get an organized feed where related articles are grouped, enabling easier comparison and comprehension of ongoing stories.
2. Customer Feedback: Understanding the Voice of the Customer
Companies receive tons of customer reviews, survey responses, and support tickets. Clustering helps make sense of all that noise.
Use case:
An e-commerce brand clustered thousands of product reviews
Clusters revealed themes like “delivery delay,” “poor packaging,” and “size mismatch”
Impact:
Instead of manually reading every review, the product and logistics teams focused on actionable clusters to drive improvements.
3. Academic Research: Literature Reviews at Scale
Researchers face the challenge of navigating millions of publications. Clustering helps organize literature into themes for easier exploration.
Example:
A university used clustering to group COVID-19 papers
Topics like “vaccine efficacy,” “variant spread,” and “treatment trials” emerged organically
Result:
Researchers found related studies faster, accelerated hypothesis testing, and avoided duplicate work.
4. Social Media Monitoring: Spotting Trends Before They Go Viral
Social platforms generate vast amounts of unstructured text—posts, tweets, and comments. Clustering allows brands and analysts to detect emerging topics or sentiment shifts early.
Real-life scenario:
A fashion retailer tracked tweets about seasonal collections
Clusters revealed unexpected buzz around a discontinued item
Outcome:
They relaunched the product, and it sold out in a week.
5. Legal and Compliance: Finding Needles in Document Haystacks
Legal teams deal with contracts, case law, and compliance documents. Clustering helps reduce the manual workload of classification and retrieval.
Use case:
A law firm used clustering to sort contracts by type and risk level
Similar clauses across documents were grouped for fast comparison
Benefit:
Time spent on contract review dropped by 40%, and legal risks were flagged more systematically.
6. HR Analytics: Employee Feedback Clustering
Internal employee surveys often contain rich insights buried in free text. Clustering pulls those patterns to the surface.
Example:
An IT company ran a pulse survey and clustered the responses
Major themes: “manager feedback,” “workload stress,” and “lack of growth”
Result:
Leadership launched targeted initiatives that improved employee retention by 15%.
These use cases prove one thing: text clustering isn’t theoretical—it’s quietly powering smarter, faster decision-making across industries. When done right, it brings order to information overload and uncovers insights you didn’t know were hiding in plain sight.
The Final Match: Choosing the Right Clustering Approach
Just like dating apps match people based on their preferences, your text clustering strategy should align with your goals, data, and available resources. Here's how to make the right choice—no ghosting involved.
1. Know Your "Why"
Before choosing a method, ask:
Are you exploring data (unsupervised)? → Go with clustering.
Do you want to group known categories? → You might need classification instead.
Example:
A content platform wanted to explore what types of blogs users were writing. Since there were no predefined categories, clustering was the natural fit.
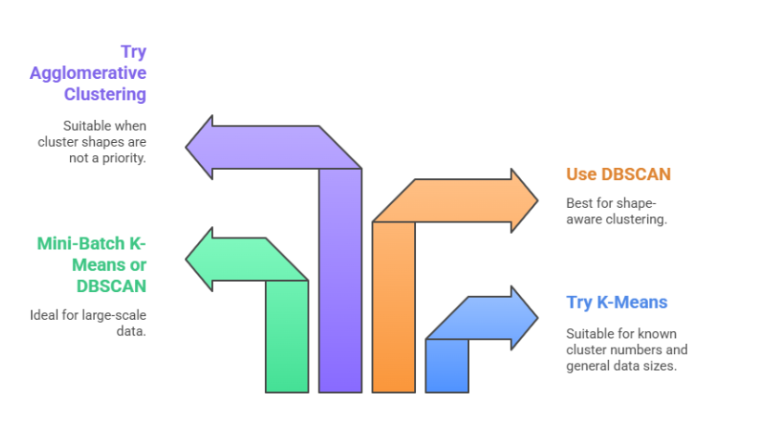
2. Understand Your Data Size
Not all algorithms are created equal when it comes to scale.
Small to medium datasets: K-Means, Agglomerative Clustering work well
Large datasets (millions of documents): DBSCAN or Scalable Mini-Batch K-Means
Example:
A startup tried hierarchical clustering on 2 million customer support tickets—it took hours. Switching to Mini-Batch K-Means cut that down to minutes.
3. Think About Interpretability
Some methods create cleaner clusters, while others are harder to interpret.
Clear boundaries needed? K-Means or Hierarchical
More organic, shape-based clusters? DBSCAN
Pro tip:
Use dimensionality reduction techniques (like t-SNE or UMAP) to visualize your clusters and make sense of them.
4. Don’t Forget Evaluation
Clustering is unsupervised, so evaluation is tricky—but not impossible.
Silhouette Score: Measures how well each point fits in its cluster
Davies-Bouldin Index: Lower is better
Manual Label Review: Always helps if you have a domain expert
Example:
An HR team used silhouette scores to choose between 3 clustering methods on employee feedback—and avoided misinterpreting vague responses.
5. Stay Iterative
Text clustering is not a one-and-done process. It’s iterative.
Try different algorithms
Tune parameters (like k in K-Means)
Revisit pre-processing techniques
Validate clusters with domain users
Think of it like relationship building—it takes time to find the perfect match.
Conclusion: Give Your Texts Their Soulmates
Text clustering is like matchmaking for your data—it brings structure to the chaos, uncovers themes, and surfaces patterns you never knew existed. Whether you're organizing news, analyzing feedback, or making sense of social media noise, clustering helps you make smarter, faster decisions.
When done right, it’s not just smart AI—it’s a superpower.