Text Classification: Categorizing Text with Machine Learning
AI's Language Sorting Hat: Putting Words in Their Perfect BoxesText Classification: Categorizing Text with Machine Learning
Introduction: Why Do We Need to Classify Text in the First Place?
Imagine you're working at a major social media company. Every minute, users are posting thousands of comments, tweets, reviews, and messages. Some are genuine questions, others are spam, a few might be toxic or harmful, and many are just everyday banter. Manually sifting through this sea of language? Impossible.
This is where text classification the art of automatically sorting text into predefined categories becomes your secret weapon.
Let’s take a quick look at how this plays out in real life:
Spam or Not? Every day, Gmail processes over 300 billion emails. Without text classification, your inbox would be flooded with phishing attempts and fake lottery wins.
Troll or Customer? Social media teams use classifiers to flag hate speech and escalate real customer issues without needing an army of human moderators.
Which Ticket Goes Where? Helpdesks like Zendesk or Freshdesk route support tickets to the right department based on just the first line of your message.
The truth is, we’re drowning in unstructured text from news articles to Instagram captions. Machines don’t just need to understand the words, they need to categorize them intelligently.
And that’s what makes text classification one of the most foundational and fascinating problems in Natural Language Processing (NLP).
In this blog, we’ll walk you through how it works, why it matters, and how you can build your own system that understands and organizes language like a pro.
What is Text Classification?Basic Definition and Everyday Examples
Text classification is the process of automatically assigning categories or labels to text data based on its content. It’s like giving a machine the ability to say, “Ah, this is a product review” or “Hmm, this sounds like spam” and to do it reliably, at scale.
Here’s a relatable example:
When you receive an email, Gmail quietly runs it through a trained model that classifies it as Primary, Promotions, Social, or Spam all before you even open your inbox. That’s text classification in action.
Some more real-world examples:
Netflix tagging movie descriptions to sort by genre or mood.
Amazon detecting fake reviews using textual patterns.
Banks classifying support tickets as “technical issue,” “account query,” or “loan request.”
Here’s a quick look at the kinds of problems text classification solves:
Spam detection
Sentiment analysis (positive, negative, neutral)
Topic labeling (e.g., politics, sports, tech)
Language detection
Support ticket routing
These categories can be as broad as “angry vs. happy customers” or as niche as “bug report vs. feature request.” The versatility is what makes this field so powerful.
Supervised vs. Unsupervised Approaches
Text classification typically comes in two flavors — supervised and unsupervised learning. Let’s break it down in simple terms.
Approach
How It Works
Real-Life Example
Supervised
Learns from labeled data (input + correct output)
A spam filter trained on a dataset of spam vs. not-spam emails
Unsupervised
Finds structure in data without labels
Grouping news articles by topic without knowing the topics in advance
Example Story:
Let’s say you’re working for a company that receives hundreds of customer feedback emails every week. With supervised learning, you first label 1000 past emails as “complaint,” “praise,” or “question.” Then you train a model on this data. With unsupervised learning, you let an algorithm cluster similar messages together — it might not name the groups, but it finds structure that humans can interpret.
In short:
Use supervised learning when you know what you're looking for.
Use unsupervised learning when you want the machine to explore patterns on its own.
How Does Text Classification Actually Work?Step-by-Step Breakdown of the Pipeline
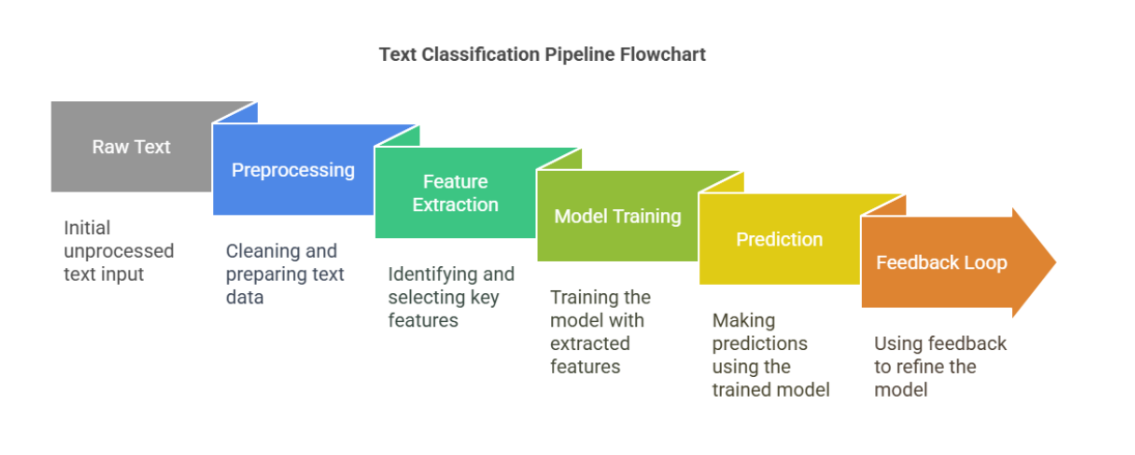
Text classification may sound magical, but under the hood, it’s a straightforward pipeline made of smart steps. Let’s break it down:
1. Data Collection
Start with a dataset — a bunch of labeled text examples. Think:
Customer reviews tagged as positive or negative
News articles labeled by category
Tweets marked as spam or not
Real-life example:
A hotel chain collects thousands of guest feedback forms. Each one is manually tagged by the support team as “service complaint,” “room issue,” or “positive feedback.” This becomes training data.
2. Text Preprocessing
Before the model can learn anything, raw text needs cleaning. This step involves:
Lowercasing everything
Removing stop words (like the, and, is)
Tokenizing (breaking text into words)
Stemming/Lemmatization (reducing words to root forms)
Story:
A company realized their model treated “running” and “run” as different features. After introducing lemmatization, accuracy improved by 9%.
3. Feature Extraction
This is where text turns into numbers — because machines don’t understand language, only math. Popular methods include:
Bag of Words: Counts how often each word appears
TF-IDF (Term Frequency-Inverse Document Frequency): Weighs rare-but-important words more heavily
Word Embeddings: Like Word2Vec or GloVe, which understand context
Quick example:
In a movie review, “The plot was thrilling and emotional” gets turned into a vector like [0.2, 0.9, 0.1, 0, ...] — ready for the model to process.
4. Model Training
Choose a machine learning model to learn patterns from these vectors:
Naive Bayes (great for text, surprisingly powerful)
Logistic Regression
Support Vector Machines
Neural Networks (like LSTMs, Transformers for deeper understanding)
Real-life tie-in:
A startup switched from Naive Bayes to a simple neural network for classifying support tickets — and cut misrouted tickets by 30%.
5. Evaluation
We test the model’s accuracy using:
Precision, Recall, F1-Score
Confusion Matrix
Cross-Validation
Example:
Imagine your model has 95% accuracy — but it’s only good at predicting the “positive” class. Evaluation helps catch that imbalance.
6. Deployment
Finally, integrate the model into a real system — like a chatbot, an email filter, or a moderation dashboard.
Use case:
Slack’s moderation bot uses a deployed classification model to silently flag inappropriate messages for review.
Popular Algorithms Used in Text ClassificationClassic ML Models That Still Work
Even with all the deep learning hype, some traditional models are still relevant — especially when you have smaller datasets or need faster results.
1. Naive Bayes
Simple yet powerful
Assumes word independence (which isn’t true, but surprisingly effective)
Real-life example:
A university’s IT team used Naive Bayes to classify helpdesk tickets. Even with just 500 labeled samples, they reached over 85% accuracy.
2. Logistic Regression
Great for binary classification
Easy to interpret and fast to train
Use case:
A news aggregation app used logistic regression to filter clickbait headlines — identifying exaggerated phrases with high precision.
3. Support Vector Machines (SVM)
Effective in high-dimensional spaces (like text)
Works well with TF-IDF vectors
Example story:
A legal tech startup used SVM to classify contract clauses by type. It helped junior lawyers find relevant sections in seconds.
Deep Learning Models: When You Have More Data (and Power)
If you have large datasets and want better contextual understanding, deep learning is your go-to.
4. Recurrent Neural Networks (RNNs)
Good for sequential data
LSTMs and GRUs are popular variations
Example:
A fintech firm used LSTM models to classify customer complaints. The model learned subtle emotional cues — like sarcasm in “Wow, thanks for locking me out.”
5. Convolutional Neural Networks (CNNs)
Surprisingly effective on text
Detects patterns and local features
Use case:
A social media tool used CNNs to spot cyberbullying patterns in chat messages — detecting word combos like “you’re worthless” or “go die.”
6. Transformer-Based Models (e.g., BERT, RoBERTa)
State-of-the-art performance
Understands deep context and semantics
Real-life application:
A recruitment platform used BERT to classify résumés by job role and skills. It could tell the difference between “Java developer” and “worked on Java coursework.”
Quick Comparison Table
Model Type
Best For
Trade-offs
Naive Bayes
Small, clean datasets
Assumes word independence
Logistic Regression
Binary/multi-class problems
Fast, but limited to linear separation
SVM
High-dimensional text data
Slower to train on large datasets
LSTM (RNN)
Sequential, emotional text
Needs lots of data, harder to train
CNN
Detecting local phrase patterns
Less context-aware than transformers
BERT
Rich, contextual classification
Resource-heavy but highly accurate
Feature Engineering and Text Preprocessing
Before your model can understand the text, it needs to be cleaned, structured, and converted into a format it can digest. This is where preprocessing and feature engineering come into play — think of it as preparing ingredients before cooking.
Step 1: Text Cleaning
This is where we remove noise — like removing junk from a signal before processing it.
Common cleaning steps:
Lowercasing
Removing punctuation
Removing stopwords (e.g., "is", "the", "and")
Tokenization (breaking sentences into words)
Lemmatization or stemming (e.g., “running” → “run”)
Real-life example:
A content moderation team at a publishing house found their classifier struggling because it treated "Awesome!" and "awesome" differently. After applying proper text cleaning and normalization, accuracy jumped by 12%.
Step 2: Converting Text to Numbers
ML models don’t understand words — only numbers. We use vectorization techniques to make this transformation.
1. Bag of Words (BoW)
Creates a vocabulary from all words and represents text as word frequency
Easy to implement, works well for simple models
2. TF-IDF (Term Frequency – Inverse Document Frequency)
Weighs rare but important words more
Helps reduce the influence of common words
Example:
An edtech platform used TF-IDF to rank forum posts for relevance. It helped surface better answers in Q&A threads, increasing engagement by 25%.
3. Word Embeddings (Word2Vec, GloVe)
Captures semantic meaning and context
Words with similar meanings are close in vector space
Story:
A customer support chatbot team trained Word2Vec on their own tickets. It learned that “refund,” “cancel,” and “money back” were similar — boosting the chatbot’s response quality.
4. Contextual Embeddings (BERT embeddings)
Considers sentence-level meaning
Differentiates “bank” in “river bank” vs “money in the bank”
Real-life win:
A job portal using BERT embeddings could now match "machine learning enthusiast" with "AI research intern" — a match traditional embeddings missed.
Quick Visual: Vectorization Techniques at a Glance
Technique
Strengths
Limitations
Bag of Words
Simple, fast
Ignores context
TF-IDF
Prioritizes important terms
Still lacks deep understanding
Word2Vec / GloVe
Captures word relationships
Struggles with polysemy
BERT Embeddings
Deep, contextual, powerful
Computationally expensive
Why Preprocessing Can Make or Break Your Model
You could be using the most advanced model in the world, but if you feed it messy, unstructured data, it won’t perform well. Clean inputs lead to clean outputs.
Real-world lesson:
An e-commerce company saw a 30% drop in classification errors just by switching from raw input to properly preprocessed and lemmatized reviews.
Training and Evaluating Your Classifier
Now that your text is clean and converted into meaningful numbers, it’s time to teach your model how to actually classify — and measure how well it learns.
Choosing the Right Machine Learning Model
There’s no one-size-fits-all. Your choice depends on the problem’s complexity, the dataset size, and performance requirements.
1. Naive Bayes
Assumes feature independence
Fast, interpretable, and surprisingly effective on many text tasks
Example:
An online news aggregator used Naive Bayes to classify article categories (e.g., Sports, Tech, Finance). With just a few hundred examples per category, it achieved over 85% accuracy.
2. Logistic Regression
Great baseline for binary classification
Simple yet powerful for many use cases
Story:
A fintech startup used logistic regression to filter spam vs. legit customer messages. Despite its simplicity, it held strong until they scaled to millions of queries.
3. Support Vector Machines (SVM)
Works well in high-dimensional spaces (like text!)
Good for small to medium datasets
4. Decision Trees / Random Forests
Interpretable and robust
Less common in raw text tasks, more popular after feature extraction
5. Deep Learning Models (RNN, LSTM, Transformers)
Handle context, long sequences, and large-scale data
Best suited when accuracy is paramount and compute is available
Real-world win:
A healthcare startup used a fine-tuned BERT model to classify medical abstracts into disease categories — improving precision in clinical recommendations.
Model Evaluation Metrics
Training is just half the job. You need to check how well your model performs — especially in real-world scenarios.
Key metrics:
Accuracy: % of correct predictions
Precision: How many predicted positives were actually correct
Recall: How many actual positives were correctly predicted
F1 Score: Balance between precision and recall
Confusion Matrix: Helps visualize true vs false predictions
Example:
An HR tool for resume screening relied solely on accuracy — until they noticed it was missing underrepresented roles. After shifting focus to F1 score, their model became more fair and reliable.
Cross-Validation and Splitting DataBest practice:
Train Set: 70% of data
Validation Set: 15%
Test Set: 15%
Use k-fold cross-validation for more reliable performance estimates, especially when the dataset is small.
Real-life story:
A legal-tech firm used k-fold cross-validation when training a clause classifier. It caught overfitting early and saved weeks of development effort.
Avoiding Overfitting and Underfitting
Overfitting: Your model learns noise from training data and fails to generalize
Underfitting: Your model is too simple and can’t capture underlying patterns
Fixes:
Use regularization
Add more training data
Try different models or features
Story from the field:
A marketing automation company saw amazing training accuracy but poor real-world performance. The culprit? Overfitting on industry-specific jargon. Switching to more generalized training examples fixed it.
Real-World Use Cases of Text Classification
Text classification isn't just a lab experiment — it's driving real value across industries. Let’s look at how it's used in the wild.
1. Spam Detection in Emails
How it works:
Models analyze the content, sender info, and even formatting of emails to decide if it’s spam.
Real-world example:
Gmail’s spam filter processes over 100 billion emails a day, using layers of models — including traditional classifiers and deep learning — to block phishing attempts and junk. It correctly filters out 99.9% of spam.
Key takeaway:
Even a seemingly simple task like spam detection relies heavily on accurate, constantly-updated classification models.
2. Sentiment Analysis in Customer ReviewsHow it works:
Classify reviews as positive, negative, or neutral based on wording, tone, and context.
Story:
A hospitality brand used sentiment analysis to monitor online reviews across hundreds of properties. It flagged common complaints like “rude staff” or “dirty bathrooms” within minutes, enabling faster service recovery.
Business impact:
Improved customer retention by 12% in one quarter by acting on classified feedback.
3. News CategorizationHow it works:
Automatically sort articles into tags like Sports, Politics, Tech, etc., to improve user experience and content discovery.
Real-world example:
Flipboard uses machine learning to personalize its magazine-style feed. It classifies thousands of new articles every day to match users' preferences and engagement patterns.
4. Social Media MonitoringHow it works:
Classifies posts to detect brand mentions, sentiment, or specific topics (e.g., complaints, trends, praise).
Case study:
A fashion brand tracked tweets during a product launch. Using real-time classification, they identified and addressed sizing issues that could’ve snowballed into PR problems.
5. Document Tagging in Enterprises
How it works:
Assigns labels to internal files (e.g., Legal, HR, Finance) for easier organization and search.
Example:
A legal firm trained a classifier to tag clauses in contracts. This slashed document review time by 30% and reduced manual errors.
6. Medical Text ClassificationHow it works:
Categorizes patient notes, medical abstracts, or clinical trial documents to assist diagnosis or research.
Example:
PubMed uses classification models to help researchers find relevant articles among millions, using tags like disease type, treatment category, and study method.
Wrap-up Thought:
Whether you're sorting spam, gauging public sentiment, or streamlining document workflows, text classification is everywhere — quietly shaping digital experiences.
Getting Started: Tools and Resources to Try Text Classification Yourself
Feeling inspired? Good. Now it’s time to roll up your sleeves. You don’t need to build everything from scratch — there are great tools and resources to help you dive in.
Beginner-Friendly Tools
Scikit-learn
Great for traditional ML models like Naive Bayes and SVM. Simple API and solid documentation. Use case: Fast prototyping on labeled datasets.
Hugging Face Transformers
Access state-of-the-art pre-trained language models like BERT, RoBERTa, or DistilBERT with just a few lines of code. Use case: Text classification with deep learning, without needing to train from scratch.
Google AutoML Natural Language
No-code option for training high-performing classifiers on your own data. Use case: Business teams with limited coding experience.
FastText (by Facebook AI)
Lightweight, fast, and surprisingly powerful for many classification tasks — even on large datasets. Use case: Multilingual or mobile-focused applications.
Datasets to Practice On
20 Newsgroups
Classic dataset with 20 categories of news posts.
IMDb Reviews
Perfect for binary sentiment classification (positive vs negative).
Amazon Product Reviews
Massive, diverse, and highly relevant for commercial use cases.
TREC Question Classification
Great for classifying questions into categories like "location", "person", or "description".
Learning Resources
Coursera’s NLP Specialization (by Deeplearning.ai)
Beginner to intermediate path with hands-on projects and model-building.
Kaggle Courses: Natural Language Processing
Free, practical, and community-backed.
Hugging Face Course
Step-by-step learning with notebooks and real-world examples focused on transformers.
Real-Life Project Idea (Try This!)
Build a news headline classifier
Scrape RSS feeds from different news categories and train a classifier to predict the category of any given headline. Bonus points if you make a simple Streamlit dashboard to showcase it.
The Future of Text Classification: Smarter, Faster, More Human
The journey doesn’t end with classifying movie reviews or categorizing support tickets. In fact, we’re only scratching the surface of what text classification can do.
Let’s peek into where this field is heading — and why it matters more than ever.
Multilingual, Multimodal, and More
As businesses expand globally, there’s an urgent need to classify text in any language — even ones with scarce training data.
Multilingual Models like XLM-R and mBERT are helping machines understand 100+ languages out of the box.
Multimodal Learning is combining text, voice, and images in a single classification model — imagine a YouTube comment being classified using the video context too.
Example:
A global healthcare provider now uses a multilingual BERT model to classify and triage patient emails written in over 25 languages — something impossible with traditional methods.
Zero-shot and Few-shot Learning
Instead of training a model on thousands of labeled examples, what if you could just tell the AI:
“Hey, classify this as urgent or non-urgent. Here's what I mean…”
That’s the promise of zero-shot and few-shot learning — techniques powered by large language models (LLMs) like GPT and T5.
No need to retrain a new classifier every time categories change.
Ideal for fast-changing industries or rapid experimentation.
Real use case:
A news startup uses zero-shot classification to instantly tag breaking news articles into dozens of evolving categories — without needing months of labeled data.
Human-in-the-Loop Systems
As powerful as these systems are, they’re even better when paired with human judgment. Future pipelines are shifting toward collaborative AI — where:
AI handles 80% of routine classification.
Humans verify edge cases, improving both trust and training data.
Pro insight:
Human-in-the-loop isn’t a crutch. It’s a strategy for building more accurate, ethical, and transparent AI systems.
Focus on Explainability and Fairness
With AI being used in hiring, credit scoring, and legal systems, it’s no longer enough to just “get it right” — we need to understand why a model made a decision.
Explainable AI (XAI) helps debug and audit text classifiers.
Tools like LIME, SHAP, and Integrated Gradients are becoming standard.
Real-world challenge:
In 2020, a large university scrapped its automated grading classifier after students flagged unexplained inconsistencies. Lesson learned? Interpretability matters.
Final Thoughts: Language Is Power — And Now, It’s Scalable
We’ve come a long way from keyword filters and hard-coded rules. Today, text classification is smart, flexible, and surprisingly accessible — from solo developers to Fortune 500s.
And tomorrow? You won’t just be classifying emails or reviews. You’ll be shaping how machines understand everything we write, say, or feel.