Multilingual Sentiment Analysis: Understanding Emotions Across Languages
Global Emotion Translator: Reading Feelings in Any LanguageMultilingual Sentiment Analysis: Understanding Emotions Across Languages
1. Introduction: Why Emotions Matter in Every Language
Imagine this: you're managing customer experience for a global e-commerce brand. One day, a product review in Hindi— (absolutely amazing) starts trending online. But your sentiment analysis tool flags it as negative. Why? Because the translation algorithm completely misread the context.
“बिलकुल बढ़िया!”
That small misfire isn’t just a technical glitch—it’s a lost opportunity to understand how your customers really feel.
The Real Challenge
In a hyper-connected world, emotions aren’t confined to one language. People express joy, frustration, sarcasm, and gratitude in thousands of dialects and cultural styles. But here's the catch:
Most AI tools are English-centric, often struggling with slang, idioms, or tone in other languages.
Translating isn’t enough context, culture, and emotion don’t always cross over cleanly.
Missing emotional cues can cost businesses in customer trust, product development, and global reach.
This is where multilingual sentiment analysis comes in not just translating words, but decoding feelings across linguistic boundaries.
Think of it as teaching machines to be emotionally multilingual.
From political opinion mining in Arabic, to real-time customer support in Spanish, to analyzing K-pop fan reactions in Korean—sentiment-aware AI is already reshaping how we listen at scale.
And in this blog, we’re diving into:
How this tech actually works (no jargon overload, promise)
The big wins and blind spots in real-life scenarios
Tools you can explore, even as a beginner
Let’s start with the basics—how machines even begin to “feel.”
2. The Building Blocks of Sentiment Analysis
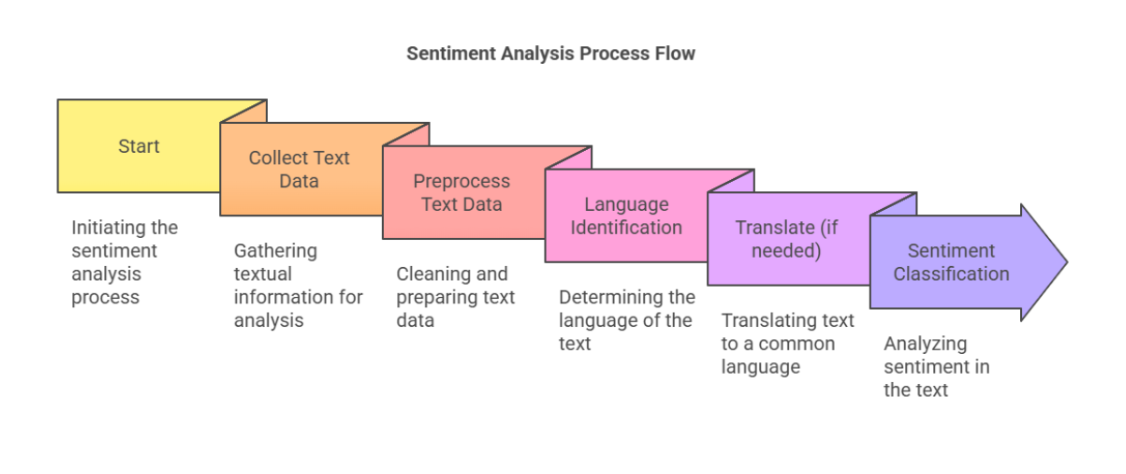
Before we get into the multilingual part, let’s first break down how sentiment analysis works in any language. At its core, sentiment analysis is the process of teaching machines to figure out: “Is this text positive, negative, or neutral?”
That might sound simple until you realize that humans barely agree on tone half the time. Just think of how easily sarcasm or dry humor can be misunderstood.
So, how do machines even begin?
They use a mix of Natural Language Processing (NLP) and machine learning to break down human text into data points they can understand.
Here’s the general flow:
Tokenization
Breaks the text into smaller pieces - like words or phrases. Example: “I love this phone!” → [“I”, “love”, “this”, “phone”]
Part of Speech Tagging
Identifies the grammatical role of each word - like noun, verb, adjective.
Word Embeddings
Words are converted into vectors- think of it as giving each word a GPS location based on its meaning. So “happy” and “joyful” end up close together.
Sentiment Scoring
Based on trained models or sentiment lexicons (basically emotional dictionaries), the system assigns scores that reflect tone:
Positive: +1
Neutral: 0
Negative: –1
All of this is powered by data- tons of labeled examples that teach the system what happy or angry language looks like.
Real-Life Example: How Netflix Uses It
Ever wondered how Netflix knows which content to recommend in different countries? They use sentiment analysis to:
Evaluate global social media reactions to shows
Understand regional trends (e.g., is a dark thriller getting unexpectedly positive buzz in Spain?)
Tailor promotional content to match emotional tone by language and region
So the next time your feed feels “weirdly accurate,” you might just be looking at emotional AI doing its job.
Now that we understand how machines process sentiment in one language, the next step is asking: What happens when there are dozens of languages involved—and emotions don’t translate directly?
That’s where the real complexity (and magic) begins.
3. Multilingual Sentiment Analysis: The Next Frontier
When you’re analyzing text in just one language, things are relatively straightforward. But once you bring multiple languages into the picture, the complexity multiplies. Language is deeply tied to culture, and sentiment isn’t always as simple as “happy” or “angry.”
So, what makes multilingual sentiment analysis so challenging?
Language Structure
Every language has its own rules of grammar, syntax, and word order. For instance, in English, we say “I love this song,” but in Korean, it’s “이 노래 좋아요” (literally “This song is good”). That difference in structure means the system must understand not just the words, but their placement and relationships within the sentence.
Cultural Nuance
Expressions of emotions vary greatly across cultures. A gesture or word might have a totally different emotional meaning in another language. For example:
In some languages, sarcasm is a big part of communication (e.g., English), while in others, it’s less common or even frowned upon.
The word “sick” in English can mean both “ill” or “amazing,” depending on context. But translating it to another language might lose that dual meaning.
Regional Slang and Idioms
When you mix slang, idioms, or local phrases into the mix, things get even trickier. Take, for example, the phrase “I’m feeling blue” in English—it means sadness, but if you translate it literally into other languages, it might not make sense at all.
A Real-Life Challenge: The Emoji Conundrum
Let’s take a closer look at how emojis can create confusion when analyzing sentiment across languages. Emojis seem universal, right? But in practice, the emotional meaning of an emoji can vary wildly depending on the cultural context.
For example: In Western cultures, the emoji is often seen as a symbol of prayer or gratitude. But in some Asian countries, it represents a bow of respect or apology.
In some parts of Europe, the emoji (the "OK" gesture) can be interpreted as an insult, especially in certain Mediterranean countries.
Real-Life Example: Facebook’s global rollout of its “Reactions” feature was tested heavily across countries, and some regions had unexpected reactions to the thumbs up/thumbs down and heart emojis. While the heart symbolized affection in most places, it was seen as too casual in more conservative regions, and the thumbs up was misinterpreted as passive-aggressive in some cultures.
The Complexities of Translation
Even more than emojis, machine translation can be a major hurdle in multilingual sentiment analysis. While tools like Google Translate have made massive strides, they still struggle with nuances, idiomatic expressions, and cultural context.
For instance, translating a phrase like "I'm not angry, I'm just disappointed" from English to Spanish might not convey the full emotional weight especially if the translation misses the subtleties of tone and intent
So, how can AI overcome these barriers and get better at understanding emotions across different languages?
4. Core Approaches to Multilingual Sentiment Analysis
Now that we understand the challenges of multilingual sentiment analysis, it’s time to explore the methods that are helping machines break through these language barriers. There are a few core approaches that researchers and developers use to teach AI to decode emotions across different languages.
1. Translation-Based Approach
One of the simplest ways to handle multilingual sentiment analysis is by translating the text into a single language (typically English), analyzing the sentiment, and then translating it back to the original language.
How it works:
Step 1: The system takes the text in the original language and translates it into English using machine translation tools like Google Translate.
Step 2: The sentiment analysis model, trained on English-language data, processes the translated text and classifies the sentiment (positive, negative, neutral).
Step 3: The sentiment is then translated back into the original language to provide the analysis.
Pros:
It’s relatively easy to implement since many NLP tools are trained on English.
Works well for languages with high-quality machine translation support.
Cons:
Loss of nuance: As we've discussed, translations often miss the cultural and emotional subtleties, leading to misinterpretations.
Accuracy issues: The quality of translation is crucial. If the translation is off, the sentiment analysis will likely be too.
Case Study: A global fashion retailer used this method to analyze reviews across multiple languages. The translations didn’t always capture sarcasm or specific cultural references, which led to misclassified feedback.
2. Multilingual Models: The Power of mBERT and XLM-RoBERTa
A more advanced approach to multilingual sentiment analysis involves pretrained multilingual models like mBERT (Multilingual BERT) and XLM-RoBERTa. These models are trained to handle multiple languages simultaneously, without the need for translation.
How it works:
These models are trained on huge multilingual corpora, meaning they can understand multiple languages at once.
They represent words as vectors (like word embeddings) that are language-agnostic, so the sentiment analysis process can occur without first translating the text.
Pros:
No translation required: This eliminates the loss of nuance and meaning in translation.
Language flexibility: Works well across many languages, even those with limited resources.
Cons:
Requires large, high-quality datasets for training, which can be expensive and time-consuming.
May still struggle with languages that have very different structures or lack large datasets for training.
Real-Life Example: Amazon uses multilingual models to analyze reviews from customers in different countries. Instead of translating all the reviews into English, they use mBERT to directly classify the sentiment in French, Spanish, and German—without needing to rely on translation tools.
3. Cross-Lingual Embeddings: A Shared Emotional Space
Another promising technique in multilingual sentiment analysis is cross-lingual embeddings, which creates a shared vector space for words and phrases across languages. This means that similar emotions or concepts are placed close to each other in this shared space, regardless of the language.
How it works:
Words in different languages are mapped to a shared space where similar meanings are close together. For example, the word “happy” in English would be close to its equivalent in French (“heureux”) or Spanish (“feliz”).
The model can then analyze sentiment without the need for direct translation, relying on the shared vector space to understand the emotional tone of the text in any language.
Pros:
Helps overcome the need for translation and provides a richer understanding of sentiment.
More accurate for languages with little translation support, especially low-resource languages.
Cons:
Requires advanced techniques to build and maintain the shared vector space.
May still struggle with languages that are highly dissimilar in structure or vocabulary.
Case Study: A global news analytics company used cross-lingual embeddings to track political sentiment in multiple languages. By mapping the emotional tones in English, Arabic, and Mandarin to a shared vector space, they could better understand the global sentiment around political events, even when there was little data available in certain languages.
These methods represent just a few of the powerful approaches being used today to navigate the complexity of multilingual sentiment analysis. But as you can see, there’s no one-size-fits-all solution—each has its strengths and trade-offs.
So, which approach should you use?
If you're just starting out and need a quick fix, the translation-based approach might work for basic tasks.
If you need something more robust and scalable, multilingual models like mBERT or XLM-RoBERTa are your best bet.
For those looking to dive deeper and tackle multiple languages with fewer translation headaches, cross-lingual embeddings could be the key.
Next up, let’s take a look at the data behind multilingual sentiment analysis—because it’s all about the right data, or things could go wrong fast.
5. Data: The Hidden Struggle in Multilingual AI
At the heart of any AI project especially multilingual sentiment analysis—is data. Without the right data, even the most advanced algorithms can fail. But gathering, curating, and processing data for multilingual sentiment analysis comes with unique challenges.
1. The Language Data Problem
The most obvious issue? Not all languages have the same amount of available data.
High-resource languages, like English, Spanish, and Chinese, have large volumes of data available from social media posts and customer reviews to news articles and books. This makes it easier for AI models to learn the nuances of sentiment in those languages.
Low-resource languages, however, don’t have enough data to train reliable models. Languages like Quechua, Basque, or even certain dialects of Arabic may not have enough labeled sentiment data to accurately train a model.
Real-Life Example: A popular AI company tried to expand its sentiment analysis tool to include several African languages. However, they quickly realized that the data required to train the model simply didn’t exist. As a result, they had to partner with local universities to gather culturally relevant text data to build their models.
2. Labeled Data: The Holy Grail of AI
While you may have plenty of raw text in multiple languages, what you really need is labeled data data that’s been tagged with the correct sentiment (positive, negative, neutral). Without this labeled data, AI models can’t “learn” what constitutes happy, sad, or angry text.
However, labeled data isn’t always easy to come by. For instance:
Manual labeling is time-consuming and costly: Labeling a dataset of thousands or millions of tweets, reviews, or comments can take weeks or months. Plus, you need native speakers who understand the emotional nuances of each language.
The emotional spectrum is subjective: One person’s “angry” might be another person’s “disappointed.” Different cultures express emotions in varying degrees and tones, and labeling them consistently across languages is a huge challenge.
Real-Life Example: A major e-commerce platform had a team working full-time to manually label customer reviews from 15 different languages. But even their native-speaking employees would occasionally disagree on the sentiment of a review, especially with complex emotional expressions like sarcasm or irony.
3. Data Quality and Diversity
Even when you do have access to labeled data, the quality and diversity of that data matter a lot.
Bias in data: If the labeled data comes from a particular region or demographic, it can lead to biased sentiment analysis. For instance, a dataset of product reviews from the U.S. might not capture how people in India feel about a product.
Diversity in emotional expression: Different cultures express emotions differently. For example, in some cultures, people may understate their emotions in public (e.g., Japanese), while in others, they may express emotions more openly (e.g., Latin American cultures). This can skew sentiment analysis if not properly accounted for.
Real-Life Example: A popular international travel website wanted to analyze user sentiment on reviews of their services. When they initially used a model trained on English-language data, they found that the system missed subtle expressions of frustration in reviews written in French. After digging deeper, they realized that French speakers were more reserved in their emotional expressions, so their frustration wasn’t always as overt as it appeared in English reviews.
4. Dealing with Multilingual Noise: Slang, Typos, and Mixed Languages
Real-world data isn’t clean. You’ll often encounter slang, typos, and even mixed languages (like “Spanglish” or “Hinglish”) that make it hard to assess sentiment accurately.
Social media is full of informal language that doesn’t follow grammatical rules. People use emojis, abbreviations, misspell words, or even mix languages in a single sentence.
Regional dialects: In many countries, people speak in various regional dialects that can be completely different from the official language. These variations can introduce unexpected sentiment shifts that a generic model might miss.
Real-Life Example: A company working on sentiment analysis for global social media content found that their model struggled with Hinglish the hybrid of Hindi and English commonly used in India. Words like “totally” were used in both English and Hindi contexts, and the model couldn't distinguish between the two without extensive retraining.
The Path Forward: Tackling the Data Struggle
So, what can be done about these data challenges?
Crowdsourcing: Companies are turning to crowdsourcing platforms to gather data, relying on native speakers to label sentiment in different languages. While this is cost-effective, it still has limitations in terms of data quality and consistency.
Transfer Learning: Some companies are using transfer learning techniques, where a model trained on one high-resource language (like English) can be adapted to other languages with less data. This can help reduce the dependency on labeled data for every new language.
Collaborations and Partnerships: Many companies are collaborating with local institutions, universities, and language experts to build diverse and high-quality datasets. By working together, they can better account for cultural differences in emotional expression.
Conclusion
In the end, data is the lifeblood of multilingual sentiment analysis and without diverse, high-quality, and labeled data, even the most advanced algorithms will fall short.
6. The Future of Multilingual Sentiment Analysis
The field of multilingual sentiment analysis is rapidly evolving. As more businesses, governments, and organizations turn to AI to understand global sentiment, new technologies and methodologies are pushing the boundaries of what’s possible. But what does the future hold for this fascinating intersection of language, culture, and technology?
1. Zero-Shot Learning: Sentiment Without Data Overload
One of the most exciting developments in multilingual sentiment analysis is zero-shot learning. Traditionally, training a sentiment analysis model required vast amounts of labeled data for each language. However, zero-shot learning allows a model to handle new languages and tasks without requiring specific training data for each language.
How it works:
Zero-shot learning enables AI systems to recognize the sentiment in a language that the model hasn’t been specifically trained on. This is accomplished by using advanced transformer models like GPT-3 or T5, which are capable of performing a wide range of tasks based on the knowledge they’ve already acquired.
The potential:
With zero-shot learning, AI models could potentially understand sentiment in hundreds of languages with little or no additional training data.
This drastically reduces the time and resources needed for data collection, labeling, and training—allowing for faster deployment across multilingual contexts.
Real-Life Example: A research project at MIT demonstrated zero-shot learning by applying it to multilingual sentiment analysis. By leveraging a single model trained on a wide range of languages, they were able to predict sentiment in languages like Swahili, Tamil, and Icelandic, even though there was minimal labeled data available for these languages.
2. Emotional Intelligence: Beyond Positive and Negative
While most sentiment analysis systems today are focused on classifying text as positive, negative, or neutral, future systems are aiming for something deeper: emotional intelligence. Instead of categorizing text into just three buckets, advanced sentiment analysis systems will be able to recognize and differentiate complex emotions.
Beyond the basics: Emotions like joy, surprise, sadness, anger, fear, and even mixed emotions (e.g., bittersweet) will be classified more accurately.
Emotion-rich data: Future AI tools will be able to understand subtle emotional expressions, such as sarcasm, irony, or context-dependent feelings like “I’m happy you’re angry” (a common expression of empathy).
Why this matters:
Recognizing a wider range of emotions will enhance AI’s ability to engage in more human-like interactions.
For businesses, it will mean a better understanding of customer satisfaction, employee sentiment, or even political opinion on a deeper, more nuanced level.
Example: Imagine a chatbot for mental health support. Instead of just understanding that a user is sad, the chatbot could identify whether they’re feeling hopeless, frustrated, anxious, or just mildly upset. This can lead to more personalized and empathetic responses.
3. Cross-Cultural Sensitivity and Bias Mitigation
A huge focus in the future of multilingual sentiment analysis is reducing cultural bias. As we’ve seen, sentiment varies greatly across regions, so ensuring that AI doesn’t misinterpret or ignore cultural nuances is crucial.
Cultural intelligence: Future models will be better at understanding not just language, but how emotions are expressed differently in various cultural contexts. For example, what’s considered “aggressive” in one culture might be viewed as direct or confident in another.
Bias detection and mitigation: AI systems will be equipped with tools to automatically detect and reduce cultural and gender biases. This will be critical for creating fair and inclusive sentiment analysis models that work equally well across different languages and cultural contexts.
Real-Life Example: Researchers at Stanford recently demonstrated how sentiment analysis models can perpetuate bias, misinterpreting certain languages or ethnic groups’ emotions. Their findings have led to new methodologies that focus on mitigating these biases by diversifying training data and fine-tuning models for cultural accuracy.
4. Real-Time Emotion Tracking for Businesses
As sentiment analysis becomes more accurate and scalable, businesses will be able to tap into real-time emotion tracking. Whether it’s monitoring brand perception, customer satisfaction, or public opinion, this capability will help organizations react quickly to changes in sentiment.
Customer service: Imagine AI-powered systems that can gauge a customer’s mood in real-time during a conversation. If a customer begins to express frustration, the system can adjust the response accordingly or escalate the issue to a human agent.
Marketing campaigns: Companies could analyze how emotions evolve around their product or service as a campaign progresses. They could tweak their messaging to better align with customers’ changing emotional states.
Example: A fashion brand could track how their customers are reacting to a new ad campaign in different regions. If sentiment begins to dip in one country, the brand could pivot their strategy in real-time to maintain a positive relationship with customers.
5. Multilingual Chatbots and Virtual Assistants: A New Era of Communication
The future is leading toward more intelligent multilingual chatbots and virtual assistants that can not only understand multiple languages but also respond emotionally to users.
These systems will be able to recognize emotions through voice or text and adjust their responses to match the emotional tone of the conversation.
Imagine speaking with a chatbot that detects frustration in your voice and adjusts its tone to a more empathetic one, or one that adapts to different emotional states depending on the language being spoken.
Real-Life Example: A major tech company is currently testing multilingual virtual assistants that can interact with users in English, Spanish, and Mandarin. The assistants are designed to understand emotional tone, such as frustration or excitement, and tailor their responses accordingly.
The Bottom Line: What’s Next for Multilingual Sentiment Analysis?
The future of multilingual sentiment analysis is bright, with advanced technologies like zero-shot learning, emotional intelligence, and cross-cultural sensitivity pushing the field to new heights. But the journey isn’t without challenges. Ensuring fair, accurate, and culturally aware sentiment analysis across many languages will require constant innovation, data diversity, and attention to detail.
One thing’s clear: the days of “translating” emotions are over. The future is about truly understanding the heartfelt emotions of people around the world no matter the language.
7. Conclusion
Bringing It All Together: The Power of Multilingual Sentiment Analysis
We’ve explored how multilingual sentiment analysis has evolved from a complex challenge into an exciting frontier in AI. The ability to understand emotions across multiple languages is transforming everything from customer service to political sentiment analysis, enabling businesses, governments, and organizations to make more informed decisions.
Here’s a quick recap of what we’ve covered:
The Challenge: Multilingual sentiment analysis is a tough nut to crack due to linguistic diversity, cultural differences, regional slang, and the subtleties of emotions in language.
Core Approaches: Methods like translation-based models, multilingual transformer models (like mBERT), and cross-lingual embeddings are helping bridge the gap, offering more accurate sentiment predictions across languages.
Data: Data plays a crucial role in building effective sentiment analysis models, and challenges like biased, low-resource languages and noisy data need to be addressed for optimal performance.
The Future: The future looks bright, with advancements in zero-shot learning, emotion recognition, and cross-cultural sensitivity promising to make sentiment analysis more accurate and inclusive.
Looking Ahead: The Role You Can Play
While we’re seeing tremendous progress, the field of multilingual sentiment analysis is still in its infancy. As AI models continue to grow more sophisticated, your involvement could help accelerate their development. Here’s how:
Stay Curious: Keep learning about new developments in AI, sentiment analysis, and NLP. Understanding how these tools work will allow you to engage with the future of language technology meaningfully.
Contribute to Data: If you’re a native speaker of a low-resource language, or if you’re involved in communities with rich linguistic diversity, consider contributing data to help improve models. Your contributions could help build a more inclusive AI that works better across the world.
Test and Adopt Tools: Businesses, especially those dealing with international markets, should experiment with multilingual sentiment analysis tools to better understand their global audience. Early adoption of these tools could provide a competitive edge in customer service, marketing, and decision-making.
Think Culturally: Whether you’re developing AI tools or interpreting their outputs, always consider the cultural context behind the emotions. Multilingual sentiment analysis is as much about understanding people as it is about understanding data.