From Launch to Lifeline: Monitoring and Scaling Your ML Models in Production
Monitoring and Scaling Deployed Models
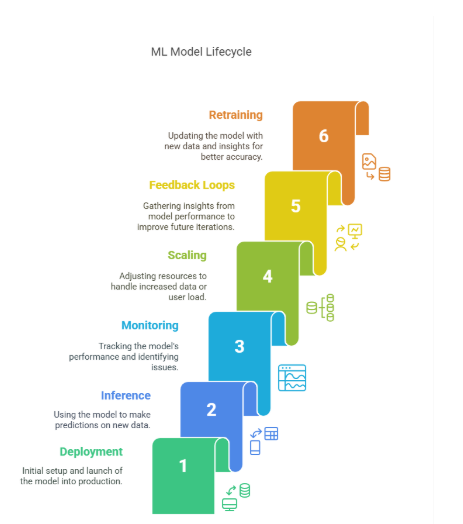
1. Introduction: The Real Work Begins After Deployment
So, you’ve trained your machine learning model. Accuracy looks great, your validation metrics are solid, and you’ve finally deployed it into production. Take a deep breath. That was the easy part.
What comes next is where the real challenge and value begins.
The Illusion of "Done"
A lot of teams celebrate deployment as the finish line. In reality, it’s just the starting point of an ongoing cycle. Models interact with real-world data that evolves, users who behave unexpectedly, and systems that fail without warning. Without robust monitoring and a clear scaling strategy, even the most accurate model can become a silent liability.
Let’s take a real-world example:
Case in point: A fintech startup deployed a credit risk scoring model that had over 92% accuracy in testing. But six weeks after launch, the company noticed a sharp uptick in loan defaults. The model had started making poor predictions. Why? A sudden shift in customer behavior due to a major regional festival had introduced unseen patterns something the model wasn't trained for. No alerts. No dashboards. Just mounting losses.
This scenario isn’t rare it’s common in companies that treat deployment as an endpoint rather than the beginning of a living system that needs care.
Why This Blog Matters
This blog is your guide to:
Understanding what model monitoring really means
Spotting subtle signals of decay before they become disasters
Scaling your ML systems gracefully as demand grows
Building MLOps strategies that keep your AI systems healthy, fair, and accountable
We’ll break down complex ideas into digestible, beginner-friendly explanations peppered with real stories and examples from the trenches of production ML.
Let’s get into the part of machine learning no one told you about but every successful tech team masters.
2. What Is Model Monitoring and Why It Matters
In the world of machine learning, models are trained on historical data. But once deployed, they encounter live, ever-changing environments. That’s where model monitoring becomes your safety net. It’s the process of continuously tracking your model’s performance, input data quality, and operational behavior to ensure everything is running as expected.
Monitoring Is Not Just for Failures
It’s easy to assume monitoring is just for detecting bugs or breakdowns. But in ML, failure often doesn’t look like an error it looks like silence. A model might keep making predictions, but those predictions might be wrong, biased, outdated, or even harmful.
Key reasons model monitoring is essential:
Model Drift: When incoming data distributions shift over time, leading to degraded performance.
Data Quality Issues: Unexpected null values, corrupted records, or changes in schema.
Latent Biases: Models may perform worse for certain subgroups over time due to evolving behavior.
Latency & Throughput Problems: Slow predictions or delayed responses affect user experience and system stability.
A Real-World Example: Drift in E-commerce
Imagine you’ve deployed a recommendation system for an e-commerce site. In December, the system sees a spike in demand for gifts and festive products. In January, that behavior changes dramatically shoppers look for fitness gear and planners.
What went wrong? Your model keeps pushing Christmas-themed products well into the New Year, leading to reduced click-through rates and lost revenue. The issue isn’t with the model itself it’s with the input data evolving without a matching retraining strategy.
With proper monitoring, such seasonal drift can be caught and addressed quickly either by triggering alerts or retraining pipelines.
Pro tip: Combine real-time monitoring with historical logging to spot trends over time not just anomalies in the moment.
The ROI of Doing It Right
Better business outcomes through more consistent predictions
Faster incident response, reducing model downtime
Improved trust with stakeholders and end-users
Compliance and fairness across demographics and geographies
3. Common Ways Models Fail After Deployment
Despite meticulous training and validation, real-world deployment exposes ML models to chaotic, unpredictable environments. And when things go wrong, they often do so silently. Let’s explore the most common ways production models fail—and how you can spot trouble before it snowballs.
1. Data Drift: Your Inputs Are No Longer What They Used to Be
Data drift happens when the input data that your model receives in production starts to differ from what it was trained on. It’s like training a dog to fetch a ball and then expecting it to fetch a frisbee without notice.
Example: A ride-sharing app trained its pricing model using pre-COVID traffic data. Once lockdowns started, traffic patterns changed drastically resulting in inaccurate fare estimates and user complaints.
How to detect:
Use Kolmogorov-Smirnov tests to compare feature distributions
Track feature-level histograms over time
Monitor sudden spikes in unseen categorical values
2. Concept Drift: The World Has Changed
Concept drift is more subtle it occurs when the relationship between inputs and outputs shifts. Even if your inputs look the same, the way they influence predictions may have changed.
Example: A loan approval model started rejecting more applicants after an economic downturn not because their features changed, but because financial behavior norms shifted post-recession.
Signs of concept drift:
Decreased model accuracy despite stable inputs
Increased false positives/negatives
Performance degradation on newer slices of data
3. Pipeline Failures and Schema Changes
You’d be surprised how often models fail because someone updated a column name or changed a CSV export format.
Example: An insurance company updated their data ingestion pipeline, converting “age” from an integer to a string. The deployed model kept running quietly predicting garbage for days until an audit caught it.
How to prevent this:
Implement schema validation tools (like Great Expectations or TFX Data Validation)
Version your data and feature pipelines
Set alerts for missing or null values in critical fields
4. Model Staleness
A model trained once and deployed forever is a ticking time bomb. Even if the model works well today, it may become outdated as new trends emerge.
Example: A news personalization engine performed well initially but failed to pick up on rapidly trending topics over time because it wasn’t retrained frequently.
Mitigation strategies:
Set up automated retraining pipelines
Use rolling windows for training data
Monitor how long it’s been since the last successful retraining
5. Latency and Scaling Bottlenecks
Even accurate models are useless if they can’t respond on time. As traffic grows, models can become bottlenecks without optimization.
Example: A healthcare chatbot’s symptom checker crashed under sudden user load during flu season because inference latency shot up from 500ms to 4 seconds.
Fixes to consider:
Batch predictions or precompute results
Use model compression or distillation techniques
Scale infrastructure horizontally using GPUs or serverless options
Summary Table: Failures at a Glance
Failure Type
Description
Example Scenario
Prevention Tip
Data Drift
Input data distribution changes
COVID-era traffic for ride pricing
Monitor input features regularly
Concept Drift
Target-output relationship changes
Loan risk post-recession
Track performance over time
Pipeline Issues
Schema or format changes in data sources
“Age” type mismatch in insurance data
Use schema validation tools
Model Staleness
Outdated model logic
News recommendations ignoring new trends
Automate retraining pipelines
Latency Bottlenecks
Inference takes too long under load
Flu-season overload in health chatbot
Scale infrastructure, optimize models
4. Tools and Techniques for Proactive Model Monitoring
The key to successful model operations isn't just building the model it’s knowing what your model is doing at all times. Think of it like flying a plane: autopilot is great, but the pilot still needs instruments and alerts to stay in control.
This section explores the most effective tools and methods to monitor your deployed models like a pro.
1. Model Performance Dashboards
Just like a car dashboard gives you speed, fuel, and temperature, a model performance dashboard shows:
Accuracy, precision, recall over time
Real-time confusion matrix updates
Drift detection metrics
Real-Life Example: A retail company using a recommendation engine built a dashboard using Evidently AI to track how product click-through rates were falling in a specific region. They discovered the local product catalog feed had broken fixing it instantly restored performance.
Popular Tools:
Evidently AI (open-source visual monitoring)
Fiddler AI, WhyLabs, Arthur AI (enterprise-grade solutions)
Grafana + Prometheus for custom monitoring setups
2. Automated Validation Pipelines
Your model may be silently failing if you aren’t validating the incoming data and predictions.
Automated checks to include:
Input schema validation (Are expected columns and types correct?)
Statistical checks (Are features within expected ranges?)
Output sanity checks (Are predictions realistic?)
Real-Life Example: A fintech app deployed a fraud detection model. Their pipeline used Great Expectations to flag when daily transaction volumes suddenly doubled catching an input duplication bug before it triggered false alarms.
Tools to try:
Great Expectations
TensorFlow Data Validation (TFDV)
Deepchecks
3. Continuous Evaluation Using Shadow Models
A shadow model runs side-by-side with your production model but doesn’t affect the outcome. It's like a backup singer quietly tracking the lead—ready to step in when needed.
Real-Life Example: A logistics startup tested a new ETA prediction model as a shadow version for a month. Only when its MAE consistently beat the production version did they make it live.
Benefits:
Compare two models on the same live data
No risk to end users
Useful for A/B testing and model versioning
4. Drift Detection Systems
Detect data and concept drift automatically with statistical monitoring tools.
Techniques used:
Population Stability Index (PSI)
Kolmogorov–Smirnov tests
Chi-square tests for categorical data
Tools that support drift detection:
Evidently AI
Alibi Detect
AWS SageMaker Model Monitor
Pro Tip: Set thresholds for acceptable drift levels. Trigger alerts or even auto-retraining pipelines when drift exceeds limits.
5. Retraining and Model Refresh Pipelines
Don't wait for performance to degrade. Build a pipeline that rechecks and retrains your model regularly daily, weekly, or monthly based on business needs.
Real-Life Example: An online ad platform saw conversion rates drop slowly. They scheduled weekly model refreshes using Kubeflow Pipelines, which helped keep CTRs stable over time without manual intervention.
Key components:
Scheduled data ingestion jobs
Periodic model training and evaluation
Automatic version comparison
Retrain only if new model outperforms old
Recap: Must-Have Monitoring Toolkit
Goal
Tool/Technique
Use Case Example
Visual monitoring
Evidently AI, Grafana
Track CTR drop in specific regions
Data validation
Great Expectations, TFDV
Detect schema changes, outliers
Performance comparison
Shadow models
Safely test model upgrades
Drift detection
Alibi Detect, Evidently
Alert on data/concept drift
Automated retraining
Kubeflow Pipelines, Airflow
Keep model fresh without manual triggers
5. Scaling Strategies – From Laptop to Production-grade Systems
Building a model that works on your local machine is a big win but it’s just the beginning. Real-world users? They demand availability, speed, and accuracy at scale. That means your model should not just work, it should scale whether it’s handling 100 or 1 million predictions a day.
Let’s explore the key strategies and real-life stories that show how scaling can make or break your ML product.
1. Understand Your Serving Patterns
Not all models need to scale the same way. Start by identifying the pattern of usage:
Batch Inference – Predictions are generated for large datasets at intervals (e.g., nightly risk scoring).
Streaming Inference – Predictions happen as data flows in (e.g., anomaly detection in IoT devices).
Real-Life Example: A healthtech company used real-time inference for predicting emergency room wait times. To scale efficiently, they used AWS Lambda for occasional predictions and scaled up to ECS Fargate during peak hours.
2. Choose the Right Deployment Architecture
You’ve got options—and choosing wisely is half the battle.
🔹 Option A: REST API Serving
Deploy your model using:
Flask/FastAPI + Gunicorn for light apps
TensorFlow Serving / TorchServe for performance-heavy models
Used when: You need a scalable web service that integrates with other apps.
🔹 Option B: Serverless Deployment
Tools like AWS Lambda, Google Cloud Functions, and Azure Functions allow for on-demand execution.
Used when: You want to serve lightweight models with occasional traffic no need to manage infrastructure.
🔹 Option C: Containerization with Docker + Kubernetes
Wrap your model in Docker and orchestrate with Kubernetes for flexible, distributed deployment.
Real-Life Example: A fintech startup containerized their credit scoring model using Docker and deployed it on GKE (Google Kubernetes Engine). They autoscaled pods based on prediction load scaling up during business hours and down after.
3. Use Model Hosting Services for Plug-and-Play Scaling
Managed platforms do the heavy lifting for you.
Top Platforms:
AWS SageMaker – Auto-scaling, endpoints, version control
Google Vertex AI – Fast deployment with explainability
Azure ML – Great for enterprises with Microsoft stack
Pro Tip: Use these if you want high availability and auto-scaling without managing Kubernetes or VM clusters.
4. Optimize for Scalability Behind the Scenes
Before you throw servers at the problem, optimize your model for performance:
Reduce model size with quantization or pruning
Use faster model architectures (e.g., switch from BERT to DistilBERT)
Cache repeated predictions where possible
Real-Life Example: A social media platform reduced inference costs by 30% just by caching predictions for repeat users and switching from a full ResNet50 model to MobileNetV2.
5. Monitor Cost vs Performance Trade-offs
Scaling isn’t just about tech it’s about ROI. Watch for:
Latency vs hardware cost
Inference time vs throughput
API uptime vs server utilization
Use Cost Dashboards: Monitor with tools like CloudWatch, Prometheus, or SageMaker Model Monitor.
Pro Tip: Don’t scale blindly. Always ask, “Is the model impact worth the cost of serving it at this scale?”
Quick Summary: How to Scale Like a Pro
Scaling Area
Tools/Strategies
When to Use
Serving type
REST API, Batch Jobs, Streaming
Depends on latency and frequency needs
Deployment model
Docker, Serverless, Kubernetes
Based on traffic, complexity, team skills
Managed platforms
SageMaker, Vertex AI, Azure ML
For quick, enterprise-grade deployment
Optimization
Model pruning, caching, compression
To improve performance before scaling infra
Cost-performance trade-off
Cloud dashboards, alerts
To avoid scaling beyond budget
6. Real-World Lessons from Monitoring and Scaling in the Wild
Monitoring and scaling sound great in theory but what do they look like in action?
In this final section, we’ll walk through three real-life scenarios that showcase the highs, lows, and “aha” moments of putting ML models into production. Each story brings a unique lesson on how teams adapt to challenges in scale, latency, and reliability.
1. When Real-Time Gets Too Real: A Ride-Sharing Startup’s Latency Battle
A ride-sharing startup launched a real-time dynamic pricing model that predicted surge pricing based on demand and weather. Initially, the model performed well in testing.
But once it went live? Chaos.
The model API latency increased to 2.4 seconds under peak load.
Riders saw inconsistent pricing between app screens.
Drivers complained of delays in fare updates.
What Went Wrong?
The model was too heavy for real-time inference.
No autoscaling policies were in place.
Lack of logging made bottlenecks hard to trace.
Fixes Implemented:
Switched to a lighter model using XGBoost instead of a deep learning model.
Deployed on Kubernetes with autoscaling enabled.
Added Prometheus + Grafana for live performance dashboards.
Lesson: Real-time use cases demand lightweight models, live dashboards, and fail-safe fallbacks.
2. The Batch Job That Broke the Bank: A Retail Giant’s Costly Oversight
A large retail company ran nightly batch inference to update personalized offers for millions of users. But one night, the model job ran out of memory and restarted again and again for 8 hours.
The Result:
$42,000 in unexpected cloud charges.
No updates were delivered to the recommendation engine.
Engineers spent two days diagnosing the issue.
What Caused It?
The data pipeline was updated, increasing data volume.
There were no monitoring alerts on compute/memory usage.
The retry policy was too aggressive without human intervention.
Fixes Implemented:
Added memory and timeout monitoring via Datadog.
Set retry caps with email/SMS alerts.
Split batch job into smaller, parallelized chunks.
Lesson: Always monitor for resource usage and set alerts on failure loops. Batch ≠ low risk.
3. Scaling for 10x Growth: A Language Learning App’s Success Story
A language learning platform introduced a speech scoring model using voice input. The feature went viral on TikTok—downloads skyrocketed.
Challenges Faced:
Model inference servers became a bottleneck.
User feedback started dropping due to delayed responses.
The ops team had only 3 engineers.
What They Did Right:
Used managed services (AWS SageMaker endpoints).
Quickly activated autoscaling and caching layers.
Set up a feedback loop via logs to identify bad requests.
Used feature flags to control rollout based on location.
Result:
They scaled from 500K to 5M DAUs in a month with zero downtime.
Lesson: Build for unexpected growth by leaning on cloud-native scaling and smart rollouts.
Key Takeaways from the Field
Monitoring should never be optional make it part of your model’s lifecycle.
Scaling is not just vertical or horizontal it’s strategic.
Real-world success depends on your ability to adapt, observe, and iterate.
Don’t just deploy and pray. Deploy, monitor, learn, and scale.
7. Conclusion: Keeping Models Alive Is a Continuous Journey
Deploying a machine learning model is often celebrated as the finish line—but in reality, it’s just the starting point of an entirely new marathon.
What separates a successful ML system from one that fades quietly into obsolescence isn’t just accuracy—it’s resilience. And that comes from observability, feedback, and the ability to grow with your users and data.
From Netflix retraining their recommendation engine to meet user shifts, to startups scaling LLM pipelines during product launches, the story is always the same: monitor early, monitor often, and scale with purpose.
Here’s your quick takeaway:
Start with basic monitoring latency, throughput, and health checks.
Build alerts for drifts because your data won’t stay the same.
Choose a scaling strategy that fits your traffic not someone else’s architecture.
Close the loop with feedback from production into retraining.
If your model's prediction power is its brain, then your monitoring and scaling system is its nervous system—constantly sensing, adapting, and responding to real-world inputs.
So go beyond the launch.
Build ML systems that thrive not just survive in production.