Introduction to Text Embeddings: Turning Text into Numbers
Cracking the Code of Language: A Beginner's Guide to Text EmbeddingsIntroduction to Text Embeddings: Turning Text into Numbers
Introduction: Why Text Needs to Become Numbers
Imagine asking your voice assistant, “What’s the weather like today?” and it replying, “I'm not sure what ‘weather’ means.” Frustrating, right?
That’s because, at its core, a machine doesn’t understand human language the way we do. Words carry nuance, emotion, and context — things we intuitively grasp, but machines struggle to comprehend. To bridge this gap, we need a way to turn our complex language into something machines can work with: numbers.
Let’s take a familiar example: Netflix. When you type "romantic comedy with a strong female lead," Netflix doesn’t just look for those exact words. Instead, it breaks your query down into numerical representations — text embeddings — that help it understand what kind of movies you actually mean, even if none of those exact words appear in a title.
So, how do we get from messy, human language to crisp, machine-readable numbers? That’s where text embeddings come in.
In this blog, we’ll explore:
What text embeddings are and why they matter
The evolution from one-hot vectors to models like BERT
Real-world use cases from Google Search to chatbots
Simple tools and visualizations to play with embeddings yourself
By the end, you'll understand not only how we turn text into numbers, but why it’s one of the most transformative techniques in Natural Language Processing (NLP) today.
What Are Text Embeddings?The Core Idea
Let’s start simple: imagine you’re trying to explain the meaning of the word “coffee” to a computer. You could try using a dictionary definition — but the machine won’t understand what “beverage”, “caffeine”, or “hot” mean either.
Instead, what if we represented “coffee” as a set of numbers that capture how it’s used in everyday language? Numbers that tell the machine, “Hey, this word is similar to ‘tea’, often shows up near ‘mug’, and probably not near ‘desert’ (unless it’s a coffee cake).” That’s the magic of text embeddings.
At its core, a text embedding is a vector — a list of numbers — that represents the meaning of a word, sentence, or even a whole document, based on its context and usage in language.
Why Do We Need This?
Machines need numbers to do math. And machine learning models, especially in NLP, are just math-heavy programs trained to find patterns. Feeding raw words directly into a model is like feeding a recipe written in Japanese to someone who only reads English.
Embedding = translation for machines.
From Words to Vectors
Let’s say you’re training a spam filter. You feed it thousands of emails labeled as spam or not spam. The words in these emails — like “winner,” “free,” or “click” — are clues.
But you can’t just give the model those words directly. You need to convert each word into a numerical format that captures how spammy it sounds.
Real-life example:
When you’re typing an email and Gmail suggests, “Let’s schedule a meeting,” that’s not magic. It’s embeddings at work. The system has learned what words and phrases often follow the ones you just typed, based on patterns across millions of messages.
Here’s a simplified flow of how this works:
You input: “Let’s schedule…”
The system converts this into embeddings (vectors)
It searches a huge database of embeddings to find what typically comes next
It suggests a relevant continuation like “a meeting” or “a call”
Embeddings help the system understand that “schedule” is often followed by an event-related word, even if it hasn’t seen that exact sentence before.
3. A Brief History of Text Embeddings1. One-Hot Encoding: The Dinosaur Era
Back in the early days of NLP, we had a crude way to represent words: one-hot encoding. Each word was turned into a binary vector with all zeros except for a one in the position that represented the word.
For example, if our vocabulary had 10,000 words, the word “coffee” might look like this:
[0, 0, 0, 1, 0, 0, ... 0]
That might sound okay, but there were three big problems:
These vectors were massive and sparse — mostly zeros.
They carried no meaning — “coffee” and “tea” looked just as different as “coffee” and “carrot.”
There was no context — every word was treated in isolation.
It’s like saying everyone in a classroom is unique because they sit in different chairs — but ignoring their personalities, interests, or relationships.
2. Word2Vec & GloVe: Giving Words a Neighborhood
Then came a game-changer.
In 2013, Google introduced Word2Vec, and suddenly, words had friends.
Instead of assigning arbitrary positions, Word2Vec used a brilliant idea: words used in similar contexts should have similar vectors.
Example:
“king” – “man” + “woman” ≈ “queen”
This opened up a new world where word relationships could be calculated with actual math.
At around the same time, Stanford developed GloVe (Global Vectors), which used word co-occurrence across a corpus to create embeddings — like counting how often “apple” appears near “fruit,”“pie,” or “iPhone.”
Real-life example:
Online shopping platforms like Amazon use these models to figure out product similarity. If you search for “wireless earbuds,” the system can also recommend “Bluetooth headphones” — even if those words weren’t in your original query — because they live near each other in vector space.
3. BERT and Beyond: Context is King
Enter BERT (Bidirectional Encoder Representations from Transformers) by Google in 2018 — and everything changed again.
Word2Vec and GloVe gave us static embeddings — the word “bank” had the same vector whether you were talking about money or rivers.
But BERT understands context.
It looks at both the left and right side of a word in a sentence, creating different embeddings for “bank” in:
“She went to the bank to deposit money.”
“They sat on the bank of the river.”
This is why modern search engines, AI writing tools, and chatbots feel eerily good at understanding your intent.
Real-life example:
Google Search today is powered by BERT. That’s how it understands you mean “how to change a flat tire” even if you search “fix car wheel puncture.” It’s not just matching keywords — it’s interpreting meaning.
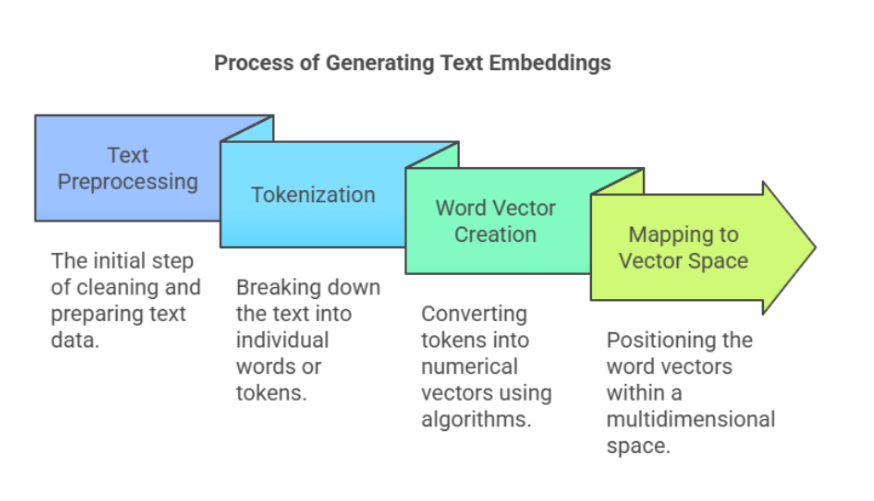
4. How Text Embeddings Work (Without the Math Headache)Step-by-Step: Turning Text into Numbers
Let’s walk through how we go from raw text to meaningful numbers, without diving deep into the math soup.
1. Tokenization – Breaking It Down
Before a machine can understand a sentence, it needs to break it into smaller parts — called tokens.
Example:
“Text embeddings are powerful.”
Becomes:
[“Text”, “embeddings”, “are”, “powerful”, “.”]
Some models go even smaller, turning words into sub-words or even characters, especially for new or rare words. This helps the model handle typos or unfamiliar terms like “textify” or “GPT-ified.”2. Vocabulary Mapping – Assigning IDs
Each token is matched to an ID from a giant vocabulary list.
Example:
“Text” → 341
“embeddings” → 1126
“powerful” → 4987
These are still just numbers, but they’re not very useful until...
3. Vector Representation – The Magic Happens
Now, each ID is mapped to a dense vector — a list of numbers like:
“Text” → [0.13, -0.28, 0.44, ...]
These vectors are trained to represent meaning, so that:
Similar words have similar vectors
Words used in different contexts get different embeddings (in models like BERT)
Think of it like Google Maps — every word is a location in a giant meaning-space. Words close together on this map tend to mean similar things.
Visualizing Embeddings in Real Life
Let’s take a real example. Suppose you have the words:
“king”
“queen”
“man”
“woman”
If you plotted their embeddings in 3D space using a tool like t-SNE or PCA, you might see:
“king” and “queen” are close together
“man” and “woman” are nearby too
The direction from “man” to “woman” is similar to the direction from “king” to “queen”
This structure means the model has actually learned gender relationships — without ever being explicitly told.
Real-life example:
When you use voice assistants like Alexa or Siri and say “Play some chill music,” the phrase gets turned into embeddings. The system knows that “chill,” “relaxing,” and “lofi” sit close together in its mental map, so it fetches what you actually meant — not just the exact words.
5. Types of Text Embeddings
Not all text embeddings are created equal. Depending on the task, different types offer different levels of context, precision, and performance. Let’s break down the major ones — with real-life examples to see where each shines.
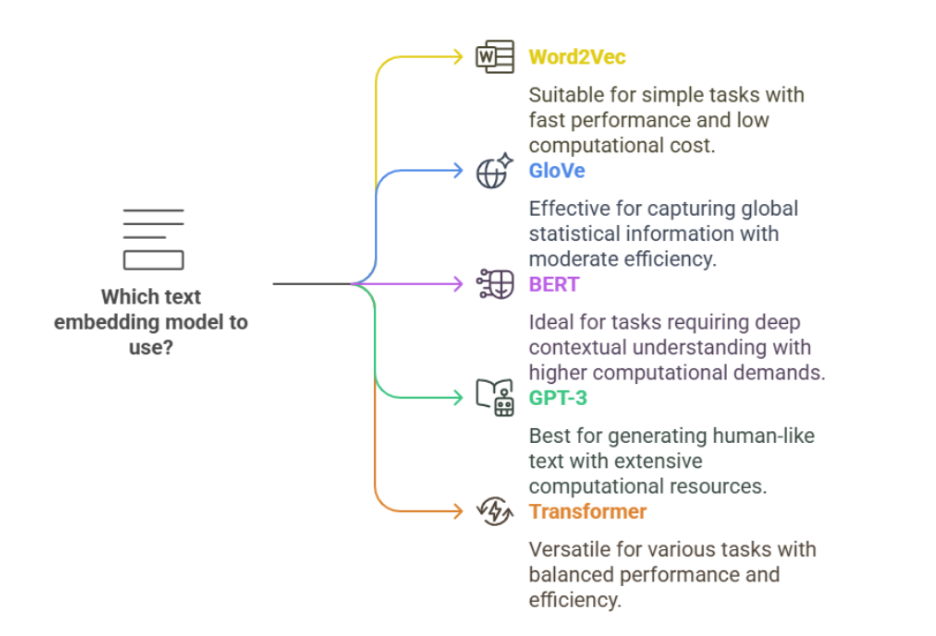
1. Word-Level Embeddings
These are the OGs — each word gets one fixed vector, no matter where or how it appears.
Popular Models:
Word2Vec
GloVe
FastTextCharacteristics:
Simple and fast
Great for capturing basic word similarity
No sense of context — “bank” always means the same thing
Real-life example:
In early spam detection systems, emails with words like “free,” “offer,” and “win” would trigger alerts because these word vectors had high similarity to spammy terms — even without understanding the full sentence.
2. Subword-Level Embeddings
These go a bit deeper. Instead of full words, they work with chunks (like prefixes, suffixes, or character n-grams).
Popular Model:
FastTextAdvantages:
Handles typos and rare words better
Understands relationships between related words like:
FastText is used in some low-resource languages and multilingual search tools because it can still make sense of unknown or uncommon words — perfect for diverse user input on global platforms like Facebook.
3. Contextual Embeddings
This is where the magic really happens. Words get different embeddings depending on the surrounding text.
Popular Models:
ELMo
BERT
RoBERTa
GPT
Why it matters:
Understands ambiguity, sarcasm, intent, and more
One word can have multiple meanings — and the model gets it right
Real-life example:
In customer support chatbots, BERT-style embeddings help the system distinguish between:
“I can’t log in to my bank account” (urgent issue)
“We had a picnic on the river bank” (no issue)
Even though the word “bank” appears in both, contextual embeddings give them very different meanings — enabling smarter, faster responses.
4. Sentence and Document Embeddings
Sometimes, it’s not about the word — it’s about the bigger picture.
Tools & Models:
Universal Sentence Encoder
Sentence-BERT (SBERT)
Doc2Vec
What they do:
Convert entire sentences, paragraphs, or even documents into a single vector
Capture intent, sentiment, and topic in one go
Real-life example:
Google Search uses sentence-level embeddings to match your long, messy queries with the right answers — even if your keywords don’t match the exact text on a page.
Say you Google:
“What’s that movie where the guy ages backward?”
Thanks to embeddings, it knows you’re talking about The Curious Case of Benjamin Button.
6. Real-Life Use Cases of Text Embeddings
Text embeddings aren't just a cool academic concept — they’re powering the tech you use every day, often without you even realizing it. Let’s look at how they show up in the real world, across industries and products.
1. Search Engines & Semantic SearchWhat happens:
When you type a question into Google like “best Italian food near me,” it’s not just looking for those exact words. Instead, it’s trying to understand what you mean.
How embeddings help:
Convert your question and all available content into vectors
Compare their similarity
Rank results based on meaning, not just keyword overlap
Real-life example:
Try searching “how to fix a jammed printer” vs. “printer paper stuck.” Google knows both mean the same thing — thanks to sentence embeddings.
2. Chatbots and Virtual AssistantsWhat happens:
When you chat with a customer support bot or say “Hey Siri, remind me to buy groceries,” it’s not just looking for keywords like “remind.”
How embeddings help:
Understand the intent behind what you’re saying
Match it to predefined actions
Even handle small talk or vague phrases
Real-life example:
E-commerce chatbots can now answer vague questions like “Do you have something elegant for a dinner party?” by understanding both "elegant" and the context of "dinner party."
3. Recommendation Systems
What happens:
When you watch a documentary on Netflix and suddenly see a lineup of mind-blowing science fiction shows recommended to you, embeddings are at play.
How embeddings help:
Convert item descriptions (e.g., movie plots, product reviews) into vectors
Compare them to what you’ve liked
Recommend semantically similar content — not just what’s popular
Real-life example:
Spotify uses embeddings to understand that if you like “chill indie acoustic,” you might also enjoy “dreamy folk pop,” even if they don’t share artists or tags.
4. Sentiment Analysis and Feedback Categorization
What happens:
Companies get tons of user reviews, social media comments, and feedback. Manually sorting them? Impossible.
How embeddings help:
Turn text into vectors
Train a model to classify sentiment (positive, negative, neutral)
Automatically group similar feedback for fast action
Real-life example:
Airbnb uses embedding-based systems to spot recurring complaints like “poor Wi-Fi” or “noisy neighborhood,” even if they’re phrased differently.
5. Plagiarism & Paraphrase Detection
What happens:
Text is compared not word-for-word, but meaning-for-meaning.
How embeddings help:
Find sentences with similar meanings but different phrasing
Great for spotting paraphrased content in essays, articles, and even code comments
Real-life example:
Educational platforms like Turnitin use embeddings to flag submissions where students reword content without actually changing the core idea.
7. How to Create Text Embeddings in Practice
So far, we’ve talked a lot about what text embeddings do — but how do you actually create them? The good news: it's easier than you might think. Whether you're a hobbyist or building a production-level NLP pipeline, there’s a method for you.
Step-by-Step: From Raw Text to Vectors
Let’s walk through the basic workflow using a real-life example — building a movie recommendation tool based on plot summaries.
1. Clean and Preprocess the Text
Before you feed text into any model, it needs a little grooming.
Typical steps:
Convert to lowercase
Remove punctuation/special characters
Tokenize (break into words or subwords)
Optional: remove stop words (like the, and, is)
Real-life example:
You scrape thousands of movie descriptions from IMDb. You don’t want punctuation or HTML tags confusing the model — clean it up before vectorizing.
2. Choose the Right Embedding Method
This depends on your use case, performance needs, and the size of your data.
Beginner options (pretrained & easy to use):
spaCy – Great for quick prototypes
Hugging Face Transformers – More powerful, supports BERT, RoBERTa, etc.
Gensim – For Word2Vec or FastText
Real-life example:
For your movie recommender, you decide to use Sentence-BERT from Hugging Face. It’s great for comparing full sentences and summaries.
3. Generate the Embeddings
You pass your cleaned text into the model — it outputs a vector, usually a list of 100 to 768+ numbers.
In Python (using sentence-transformers):
Python
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')
sentence = "A retired hitman seeks revenge against the mafia."
embedding = model.encode(sentence)
print(embedding.shape) # (384,)
Each vector now represents the meaning of the sentence in multi-dimensional space.
4. Use Embeddings for Your Task
Once you’ve embedded the text, the sky’s the limit. You can now:
Compare vectors for similarity
Cluster them for topic modeling
Feed them into a classifier or recommendation engine
Real-life example:
In your movie tool, you embed the plots of all available films. When a user enters a favorite movie, you embed that plot too — then return the top 5 closest plots by cosine similarity.
Bonus: Use Vector Databases for Scale
If you're working with large datasets or deploying to production:
Use FAISS, Pinecone, or Weaviate to store and search embeddings efficiently.
These tools let you perform real-time semantic search across millions of documents.
Real-life example:
A recruitment platform uses FAISS to match resumes with job descriptions in milliseconds — using vector similarity instead of traditional keyword filters.
8. Challenges and Limitations of Text Embeddings
Text embeddings are powerful, but like any tool, they come with their own set of challenges. Knowing their limitations helps you choose the right models, avoid blind spots, and build better NLP systems.
Let’s unpack a few common pitfalls — and how to work around them.
1. Context Loss in Basic EmbeddingsWhat’s the issue?
Earlier embedding methods like Word2Vec or GloVe generate one vector per word, no matter the sentence.
Why that’s a problem:
Words can have multiple meanings depending on context.
Real-life example:
The word "bank" in “river bank” vs. “savings bank” would get the same vector in GloVe — even though the meanings are completely different.
This can confuse models that rely on those embeddings.
Workaround:
Use contextual embeddings like BERT or GPT-based models that generate different vectors depending on surrounding words.
2. High Computational Costs
What’s the issue?
Advanced models like BERT or RoBERTa are resource-intensive.
Why that’s a problem:
Slower performance for real-time systems
May require powerful GPUs or cloud resources
Real-life example:
Imagine trying to build a customer support bot that responds instantly — running BERT for every incoming message might introduce lag.
Workaround:
Use distilled models like DistilBERT or MiniLM for speed
Precompute embeddings for frequently used text
3. Embeddings Can Be BiasedWhat’s the issue?
If the training data contains biased language (e.g., gender, race), embeddings can reflect and amplify those biases.
Real-life example:
Early word embeddings associated “man” with “computer programmer” and “woman” with “homemaker.”
Why it matters:
These biases can affect applications like hiring tools, sentiment analysis, and more — causing real harm.
Workaround:
Use debiasing techniques
Audit and test your embeddings, especially in high-stakes applications
4. Poor Performance on Domain-Specific TextWhat’s the issue?
Generic embeddings trained on Wikipedia or news data may not understand medical, legal, or financial jargon.
Real-life example:
A legal chatbot using generic BERT might misinterpret “discovery motion” or “amicus brief” as everyday words.
Workaround:
Use domain-specific models (e.g., BioBERT for medical text)
Fine-tune a general model on your dataset
5. Dimensionality & Storage OverheadWhat’s the issue?
Embedding vectors are often 300–1000+ dimensions long. Multiply that by millions of documents, and storage becomes a problem.
Real-life example:
A company storing embeddings for every customer support chat may hit performance bottlenecks when scaling.
Workaround:
Use dimensionality reduction (PCA, UMAP)
Store only what's needed or use vector databases optimized for this
Text embeddings are impressive — but they’re not magic. Being aware of these limitations helps you choose wisely, tune intelligently, and build NLP applications that are accurate, fair, and scalable.
9. What’s Coming Next in the World of Embeddings?
As we’ve seen, text embeddings are a game-changer in the field of NLP and machine learning. But this is just the beginning. The field continues to evolve rapidly, with new models, techniques, and applications emerging. Let's take a look at the trends that will shape the future of embeddings.
1. Multilingual and Cross-lingual EmbeddingsWhy It Matters:
With the rise of global applications, multilingual embeddings will be a game-changer. Imagine embedding not just one language but multiple languages in the same vector space. This will make it possible to build tools that can understand and translate text seamlessly across languages
Real-life example:
A global e-commerce site wants to let users search in their native languages, but the product descriptions are in multiple languages. Using multilingual embeddings like mBERT or XLM-R, the site can search across languages without having to manually translate every product description.
What’s next:
mBERT (Multilingual BERT) and XLM are already making strides in multilingual understanding. Expect faster and more accurate cross-lingual models in the future.
2. Better Bias Mitigation in EmbeddingsWhy It Matters:
Bias in machine learning models, especially text embeddings, is a significant concern. Embeddings can inherit societal biases, leading to harmful stereotypes in applications like hiring, policing, or healthcare.
Real-life example:
Consider a hiring algorithm trained on biased text data — it may unfairly favor certain genders or ethnic groups. This is a problem that many companies are working hard to solve.
What’s next:
Researchers are actively developing debiasing techniques for embeddings, such as Hard Debiasing and Bias Correction Networks. As a result, expect safer, fairer models that mitigate bias more effectively in the near future.
3. Fine-Tuning and Domain-Specific EmbeddingsWhy It Matters:
Generic embeddings may work well for general language tasks, but domain-specific language — like legal, medical, or technical jargon — often requires specialized embeddings.
Real-life example:
A law firm might use LegalBERT or ContractBERT to process contracts. These models are trained specifically on legal texts, understanding terminology that a general-purpose model might not.
What’s next:
Expect more fine-tuning options for specialized industries and fields. Companies will likely create and release pre-trained embeddings for niche markets, reducing the time and cost of model training.
4. Real-Time and Interactive Embedding SystemsWhy It Matters:
As machine learning models get more efficient, real-time applications like interactive chatbots, dynamic content recommendation, and personalized search will become more commonplace.
Real-life example:
Imagine an online tutor that uses embeddings to analyze a student’s question, process it, and respond with a personalized lesson in real-time. That’s a powerful application of text embeddings in education.
What’s next:
Advances in model compression and distilled models (like DistilBERT) will make it possible to deploy real-time NLP systems that use embeddings for personalized interactions without requiring massive computational resources.
5. Transformers Beyond NLP: Multimodal EmbeddingsWhy It Matters:
Text embeddings are powerful, but what if you could combine text with images, videos, and speech? Multimodal embeddings aim to unify different types of data into a single vector representation. This would open the door to new applications in fields like autonomous driving, healthcare, and entertainment.
Real-life example:
In the future, a self-driving car might use embeddings that combine text (traffic signs), image (road conditions), and speech (driver instructions) into one integrated system. This could allow the car to understand complex scenarios and make better decisions.
What’s next:
Look for growing interest in multimodal transformers like CLIP and DALL-E, which combine image and text data for tasks like image captioning, visual search, and even generating images from text prompts.
These advancements show that the world of embeddings is not just evolving — it’s expanding. As models become more versatile, smarter, and efficient, the applications will continue to grow across industries, making AI even more intuitive and transformative.
10. Conclusion
Text embeddings have revolutionized how machines process and understand human language. By converting words, sentences, or even entire documents into numerical vectors, embeddings allow computers to perform tasks like semantic search, sentiment analysis, and text classification with remarkable accuracy.
Key Takeaways:
What Are Text Embeddings?
Text embeddings convert text into high-dimensional vectors, representing semantic meaning in a format that machines can understand. The most popular models include Word2Vec, GloVe, BERT, and others.
How Embeddings Work
By training on large amounts of text, embeddings capture relationships between words based on context. Similar words are positioned closer together in the vector space, while words with different meanings are far apart.
Real-World Applications
From search engines and chatbots to recommendation systems and sentiment analysis, text embeddings are used in a wide variety of applications. These tools enhance user experiences by enabling more natural and intuitive interactions.
Challenges and Limitations
Despite their power, text embeddings can suffer from biases, limited context understanding, and high computational costs. Advanced models like transformers aim to address these issues, but challenges remain.
Future Directions
The future of text embeddings includes multilingual capabilities, bias mitigation, fine-tuning for specific industries, and even multimodal embeddings that combine text with other data types like images and audio.
In summary, text embeddings are the backbone of modern natural language processing, enabling machines to understand language in ways that were previously impossible. Whether you're building a chatbot, a search engine, or a recommendation system, understanding how embeddings work and how to leverage them will be critical to creating intelligent, human-like applications.