Few-Shot Classification: Learning with Minimal Data
AI's Superhuman Cheat Code: Learning Crazy Fast with Tiny HintsFew-Shot Classification: Learning with Minimal Data
Introduction: The New Age of AI Learning
Imagine this: you're shown two pictures of a zebra, and suddenly, you can recognize zebras anywhere on a safari, in a zoo, or even in a cartoon. Now, imagine a machine doing the same. That’s not science fiction anymore; it’s the magic of few-shot classification, a cutting-edge field in artificial intelligence that allows models to learn from just a handful of examples.
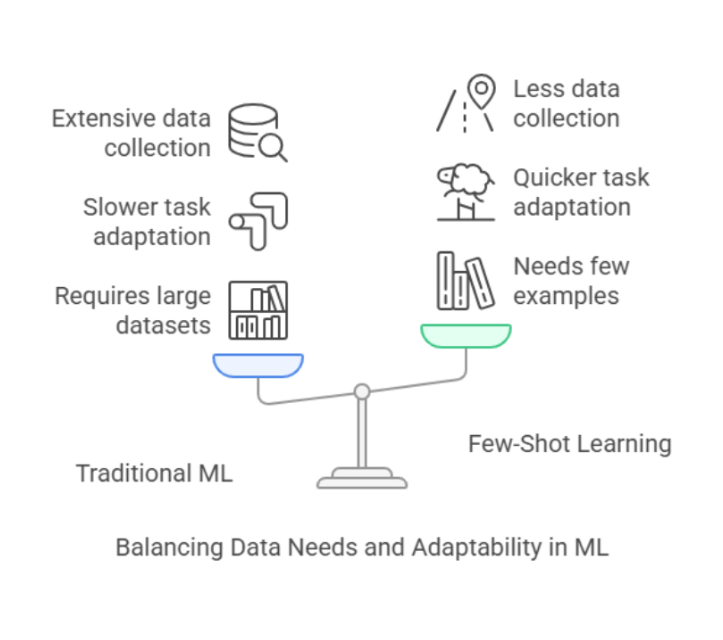
Traditionally, AI models have been like overeager students they need thousands, even millions, of labeled examples to understand a new concept. Want to teach a model to spot a banana? You’d better have an entire fruit basket worth of data. But few-shot classification flips the script: it enables machines to generalize and perform tasks with limited training data sometimes just 2–10 examples.
very
In a world where data is expensive, privacy is critical, and speed is everything, few-shot classification is becoming the superhuman cheat code of AI. It’s not just making learning faster; it’s making it more human.
In this blog, we’ll dive into:
What few-shot classification actually means (without the jargon),
How it works under the hood,
Real-world stories where it's already making a huge difference,
Tools and frameworks you can start using today,
And why this matters to tech professionals, startups, and everyday AI users.
Ready to learn how AI is learning to learn—faster than ever before? Let’s dive in.
What is Few-Shot Classification, Really?From Big Data to Barely Any Data
For years, machine learning thrived on one belief: the more data, the better the performance. But collecting and labeling massive datasets is time-consuming, expensive, and often not feasible especially in areas like rare disease detection or niche product recognition.
Few-shot classification challenges that old thinking. It enables models to accurately classify or understand new categories with only a few labeled examples sometimes as few as 2 to 5 .
Let’s break it down:
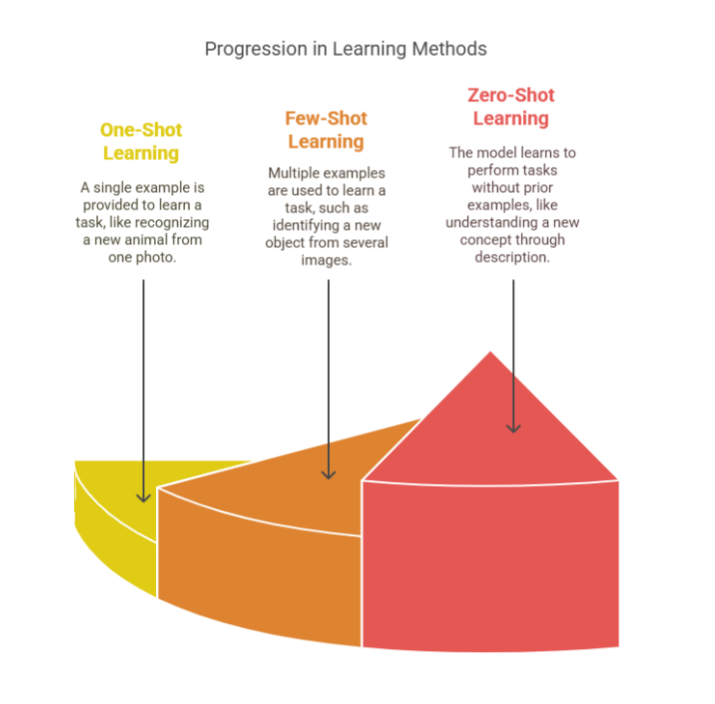
Zero-shot learning: No examples are given. The model must rely on pre-learned knowledge.
Example: ChatGPT answering a question about a new topic it hasn’t explicitly seen before.
One-shot learning: The model learns from a single example.
Example: Face ID on your phone recognizing you from just one initial scan.
Few-shot learning: The model sees 2–10 examples to learn a new class or concept.
Example: Teaching a vision model to recognize a new type of bird using only a handful of photos.
So how is this possible? Few-shot learning doesn't start from scratch. Instead, it builds on prior knowledge, much like how you might recognize a new kind of pasta because it resembles ones you’ve already tried.
A Beginner-Friendly Analogy
Think about how quickly humans learn. Suppose you show a child two pictures of a platypus and tell them what it is. Next time they see one even in a cartoon they’ll probably recognize it. Why? Because humans are incredibly good at transferring knowledge from previous experiences.
Few-shot classification mimics this cognitive ability. The model doesn’t just memorize patterns it learns how to learn.
Real-world analogy:
A chef who’s mastered hundreds of recipes can usually recreate a new dish just by tasting it once or seeing the ingredients. That’s few-shot learning in the kitchen.
For AI, few-shot classification does the same. It equips models with the ability to quickly adapt to new tasks using what they’ve already learned—reducing the dependency on massive datasets and opening doors to faster, leaner AI development.
How It Works Under the HoodThe Secret Sauce: Meta-Learning
Few-shot classification isn’t just about clever shortcuts it’s built on a powerful concept called meta-learning, or "learning to learn."
Instead of training a model to recognize specific categories, meta-learning trains the model to adapt quickly to any category, even if it’s never seen it before. It’s like teaching a student how to learn any subject, rather than drilling them on just one.
Let’s simplify:
Traditional training:
“Here are 10,000 dog images. Learn what dogs look like.”
Meta-learning:
“Here are a bunch of tasks where you must learn something new with just a few examples. Learn how to learn quickly.”
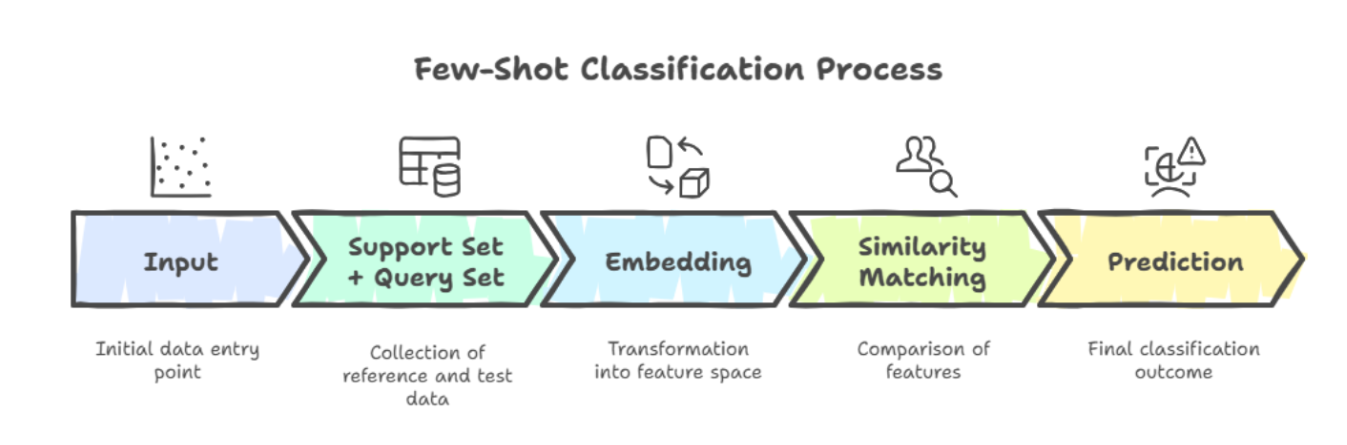
The Role of Support and Query Sets
Few-shot learning often uses an episodic training setup with two key ingredients:
Support Set: A small number of labeled examples (the “few shots”).
Query Set: Unlabeled data the model must classify using what it learned from the support set.
Think of it like this:
Support Set = Your study notes before a quiz
Query Set = The actual quiz questions
The model is trained through hundreds or thousands of these mini-quizzes (episodes), each with new tasks and new classes, so it gets really good at adapting fast.
Popular Architectures & Techniques
Here are some frameworks and methods that power few-shot classification:
Prototypical Networks
Learns a prototype (average) representation of each class and measures how close a new example is to these prototypes.
Real-life example: Think of comparing someone’s handwriting to a known signature template.
Matching Networks
Compares each new query directly with examples in the support set using similarity functions.
Real-life example: Tinder for image classification—find the best match.
MAML (Model-Agnostic Meta-Learning)
A meta-learning approach that trains the model's parameters to be adaptable with just a few steps.
Real-life example: A generalist athlete who can quickly adjust to any sport after a quick warm-up.
Why It Actually Works
It sounds almost magical—but there’s logic behind it. Few-shot models succeed because of:
Transfer Learning: Leveraging vast pretraining on large datasets to generalize to new tasks.
Embedding Spaces: Mapping data into a vector space where "similar" examples are closer together.
Metric Learning: Teaching the model to compare and measure similarity, not just classify.
4. Few-Shot Learning in Action: Real-World Use Cases
1. Medical Diagnosis with Limited Data
In healthcare, getting large labeled datasets can be nearly impossible—especially for rare diseases. Few-shot learning comes to the rescue by allowing models to learn from just a handful of annotated cases.
Example:
Imagine trying to detect a rare genetic disorder with only five known patient scans. A few-shot model trained on similar tasks (e.g., identifying patterns in MRI scans) can generalize its knowledge and still flag potential cases with surprising accuracy.
Why it matters:
Saves time and resources
Enables AI in underserved medical areas
Supports early diagnosis where speed is critical
2. Personalized Virtual Assistants
Virtual assistants often need to adapt to you—your tone, commands, and personal context. With few-shot learning, they don’t need to hear you 1,000 times to get it right.
Example:
Train a voice assistant to recognize your preferred way of asking for weather updates—just a few examples of how you phrase it, and it gets smarter fast.
Benefits:
Hyper-personalization
Low training cost per user
Better user experience with minimal input
3. Visual Recognition for Niche Products
E-commerce platforms struggle with categorizing and tagging niche or new products that aren’t in their standard catalog.
Example:
Let’s say you launch a line of eco-friendly handmade bamboo speakers. Few-shot learning lets the model learn your product type from just 3–4 labeled photos and automatically tag future listings with the same features.
Outcomes:
Faster product onboarding
Improved search and discovery
Support for long-tail items
4. Fraud Detection in Financial Services
New types of fraud emerge constantly, and models need to detect them before they become widespread—often with very few examples.
Example:
If only three recent transactions from a new scam pattern are identified, a few-shot model can generalize and begin catching similar anomalies in real time.
Impact:
Early response to evolving threats
Reduced reliance on large fraud databases
Adaptability to unseen attack vectors
5. Robotics and Automation
Robots typically require extensive training to learn a new task. Few-shot learning flips that.
Example:
A warehouse robot learns how to stack a new type of box after being shown just a few demonstrations—no need to retrain from scratch.
Advantages:
Rapid task generalization
Lower training time per task
Greater autonomy in dynamic environments
Challenges and Limitations of Few-Shot Classification
Few-shot learning might sound like the holy grail of machine learning—but it’s not without its own set of dragons to slay.
1. Sensitivity to Task Design
Few-shot models heavily rely on how you set up the support and query sets. Poorly chosen examples can throw everything off.
Example:
If the support set has blurry or mislabeled images, the model can misinterpret the entire task—like trying to learn chess rules from watching someone play checkers.
Why it’s tricky:
Requires thoughtful task sampling
Quality > quantity
Small errors have big consequences
2. Domain Shift and Generalization Limits
Training a model on animal photos and expecting it to classify industrial parts with just a few examples? That’s asking for trouble.
Real-life analogy:
Imagine teaching someone French, then handing them an Italian newspaper and expecting them to understand it fluently after seeing two headlines.
What to watch out for:
Performance drops if the test domain is too different
Needs careful pretraining or domain adaptation strategies
3. Overfitting on the Few
Few-shot learning walks a tightrope too much learning, and it memorizes the few examples. Too little, and it learns nothing at all.
Example:
A model shown three images of a cat in weird poses might learn to associate “cat” with those specific angles, failing to recognize the next normal cat image.
Problem areas:
High variance
Fragile generalization
Needs regularization techniques like data augmentation or contrastive learning
4. Computational Demands of Meta-Learning
Although few-shot tasks need less data at inference, training a model to learn how to learn requires a lot of computation upfront.
Real-life comparison:
It’s like spending months training a rescue team how to handle every emergency scenario possible so they can respond to any one in seconds.
Cost factor:
High training time
GPU-intensive
Not always accessible for small teams or startups
5. Evaluation is Tricky
Standard metrics like accuracy or precision don’t always paint the full picture in few-shot learning. Evaluating across many random tasks is key but also complex.
Why it matters:
Performance can vary wildly from one task to another
Hard to compare models apples to apples
Needs robust benchmarking frameworks
Despite these hurdles, few-shot classification continues to evolve rapidly. Researchers are actively developing smarter meta-learning strategies, better embeddings, and more efficient training pipelines to overcome these roadblocks.
The Future of Learning with Less
Few-shot classification isn’t just a research novelty it’s becoming central to how we build smarter, faster, and more flexible AI systems. As the data-hungry days of deep learning give way to efficiency and adaptability, this technique is paving the road ahead.
1. Towards More Human-Like Learning
Humans don’t need 1,000 examples to understand something new. Few-shot models aim to replicate this.
Example:
A child sees a platypus once and remembers it for life. Imagine AI with that kind of intuition understanding new categories or objects after just one or two examples.
What’s next:
Research is focusing on common sense priors and world knowledge
Integration with large language models to add reasoning abilities
Closer alignment with cognitive science models
2. Democratization of AI Development
Few-shot learning allows teams with limited resources to build competitive AI models without massive datasets or cloud bills.
Example:
A nonprofit in a developing country wants to build a wildlife detection system. With few-shot learning, they don’t need thousands of labeled images just a small set and the right pretrained model.
Future vision:
More accessible tooling
Easier model deployment at the edge
AI development for niche or low-resource domains
3. Multimodal Few-Shot Learning
The next evolution is teaching models across multiple input types images, text, audio, and more—all at once.
Example:
An AI assistant that learns a new task by watching a short video tutorial, reading a couple instructions, and listening to one user demo—all with minimal supervision.
Emerging Trends:
Unified multimodal architectures (like CLIP and Flamingo)
Cross-domain task generalization
New benchmarks that combine vision, language, and audio tasks
4. Integration into Prompt-Based AI Systems
Few-shot classification is now merging with prompt engineering, especially in large language models like GPT-4 and Claude.
Example:
Give a few examples of sentiment-labeled reviews in a prompt, and the LLM figures out how to classify the next review. No fine-tuning required.
What this means:
Training-free few-shot learning
Rapid prototyping
Powerful APIs for custom workflows
5. Fewer Shots, Better Results
Eventually, the goal is to go beyond few-shot into one-shot or even zero-shot learning, where models generalize without any new examples.
Current direction:
Zero-shot tasks using foundation models
Self-supervised learning and large-scale pretraining
Transfer learning with even less data
Few-shot learning isn’t just a technical trick it’s a paradigm shift. One that’s driving us toward leaner, more intuitive AI systems that don’t just consume data, but truly understand it.
Conclusion: Learning to Learn, the Smarter Way
Few-shot classification flips the script on traditional machine learning. Instead of devouring thousands of examples, it teaches models to do more with less mimicking the human ability to grasp new concepts quickly and intuitively.
From solving real-world problems in healthcare and wildlife conservation, to enhancing the flexibility of next-gen AI assistants, few-shot learning is already reshaping how we think about intelligence. Sure, it’s not perfect. Challenges like task sensitivity, generalization, and training complexity still exist but the direction is clear.
This isn’t just faster learning it’s smarter learning. The kind that unlocks opportunities for small teams, lean startups, and global use cases where data is scarce but needs are real.
As research evolves and few-shot models mature, we’re getting closer to an AI that doesn’t just need less data—it needs less instruction.