Dense Retrieval: Finding the Most Relevant Documents
Document Treasure Hunt: Finding Exactly What You Need
Dense Retrieval: Finding the Most Relevant Documents
1. Introduction: The Document Discovery Dilemma
We’ve all been there trying to find an important document buried under layers of irrelevant files. Whether it’s an email, report, or contract, the search process often feels like a treasure hunt without a map.
The Frustration of Traditional Search Systems
Keyword-based search: You type in the exact terms you think are relevant, but the results are either too broad or not what you’re looking for.
Limited scope: Searching for "freedom of speech" might not return results containing phrases like "expression rights" or "first amendment," even though they’re contextually similar.
Traditional search engines rely heavily on matching words. But, as we know, language isn’t so straightforward. The same concept can be expressed in countless ways, which is why you might still struggle to find what you need.
Enter Dense Retrieval: A Smarter Way to Search
Dense retrieval changes the game by going beyond just matching words. Instead, it focuses on the meaning behind your search. Here’s how it works:
Meaning over words: Dense retrieval uses machine learning to understand what you're asking and find semantically similar documents, even if the exact words don't match.
Context matters: It interprets your query in a way that connects it to the intent behind documents, not just surface-level keywords.
In this blog, we’re going to explore how dense retrieval works, what makes it different from traditional search, and how you can use it to find exactly what you need faster, smarter, and more efficiently.
Stay with us as we uncover:
What dense retrieval is and how it works
Real-life examples of how it's used (think chatbots and legal databases)
Practical tools and techniques to start implementing it in your own projects
Let’s dive into the world of dense retrieval and discover how it can transform the way we search for information.
2. What is Dense Retrieval?
Dense retrieval is a revolutionary approach to information search that focuses on understanding the meaning behind the query and the documents, rather than just matching specific words or phrases. It leverages advanced machine learning models, such as transformers, to process and compare documents based on their semantic content. Let’s break it down further.
The Basics of Dense Retrieval
At its core, dense retrieval is based on the concept of embeddings numerical representations of text that capture the meaning of words and phrases in a multi-dimensional space. Here’s how it works:
Text to vectors: Each document or query is converted into a high-dimensional vector (a list of numbers) that represents its semantic meaning.
Comparing meaning: Instead of searching for exact matches of keywords, the search system compares the vectors to find semantically similar results.
Using neural networks: Dense retrieval uses powerful models like BERT or Sentence-BERT to generate these embeddings, allowing it to understand context, synonyms, and variations in phrasing.
Real-Life Example: Searching a Legal Archive
Imagine a lawyer searching a massive database of legal precedents. They need documents related to “freedom of expression,” but the search query could be phrased in many different ways:
Traditional search might only return documents containing the exact keywords “freedom of expression,” missing relevant results that use synonyms or related terms.
Dense retrieval, however, can find documents that discuss the same legal principles using different language, such as “speech rights,” “first amendment,” or even “censorship laws.”
In this example, dense retrieval doesn’t just rely on the words you type; it understands the meaning behind the legal concepts you’re searching for and retrieves the most relevant documents based on context, not just keywords.
Dense vs Sparse Retrieval: A Quick Comparison
Sparse retrieval: Relies on exact keyword matching. It’s fast but limited in flexibility.
Dense retrieval: Focuses on semantic meaning by using embeddings. It’s slower but much more accurate in understanding context.
While dense retrieval is more resource-intensive, its ability to understand language at a deeper level makes it invaluable for complex search tasks, especially in large document databases.
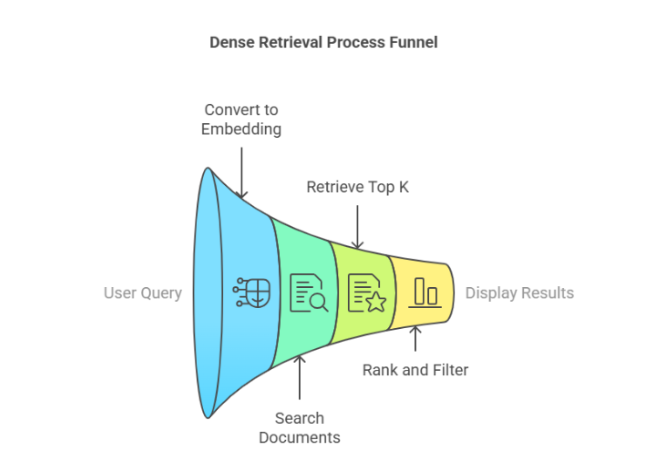
3. How Does Dense Retrieval Work?
Dense retrieval works by transforming both queries and documents into numerical vectors, which are then compared to find the most relevant results. This process is underpinned by powerful machine learning models that understand the meaning behind words rather than just matching keywords.
Step-by-Step Breakdown of Dense Retrieval
Encoding the Query and Document
Embedding the query: When a user enters a search query, the system converts it into a vector using a pre-trained model like BERT or Sentence-BERT. This vector represents the semantic meaning of the query.
Embedding the documents: Each document in the database is also converted into a vector in the same way. The system essentially creates a "map" of all documents based on their meaning.
Storing the Vectors
These vectors are stored in a specialized database or index. Unlike traditional systems that store documents in raw text format, dense retrieval systems store them as vectors, which allows for efficient comparisons.
Comparing Vectors
When a query vector is created, the system compares it to all the document vectors in the database using similarity measures like cosine similarity or Euclidean distance. The system looks for documents whose vectors are closest to the query vector in this multi-dimensional space.
Ranking results: Documents that are most similar (in terms of meaning) to the query are ranked higher and returned as search results.
Retrieving the Most Relevant Documents
The system then returns the documents that are most relevant to the query based on their vector similarity. This allows for more accurate results, even if the exact keywords aren’t present in the documents.
Tools of the Trade: Popular Models and Libraries
Dense retrieval relies on several advanced tools to perform these tasks efficiently:
Sentence-BERT: A modified version of BERT that’s specifically designed to create embeddings for sentences and short paragraphs.
ColBERT: Another model that optimizes the retrieval process by providing a combination of dense and sparse methods for faster, more accurate results.
DPR (Dense Passage Retrieval): A model developed by Facebook AI that focuses on improving document retrieval using dense vectors.
Additionally, there are several open-source libraries and platforms that help implement dense retrieval:
FAISS: A popular library for similarity search and clustering, which helps efficiently index and search vectors.
Haystack: An open-source framework for building search systems that support dense retrieval.
Weaviate: A cloud-native vector search engine that provides an easy way to build semantic search capabilities.
Real-Life Analogy: Music Recommendation Systems
Dense retrieval can be compared to how music streaming services recommend songs. Instead of recommending tracks based on exact matches (like searching for a specific genre), these systems analyze the musical elements (tempo, mood, style) and recommend songs that are semantically similar to what you’re currently listening to.
Similarly, in dense retrieval, instead of finding documents that match the query exactly, the system finds documents that are contextually or semantically similar based on meaning and intent.
4. Dense vs Sparse Retrieval: Which One Should You Use?
When it comes to choosing the right retrieval method for your project, understanding the strengths and weaknesses of both dense and sparse retrieval is essential. Let’s dive into the key differences between these two approaches and explore which one might suit your needs.
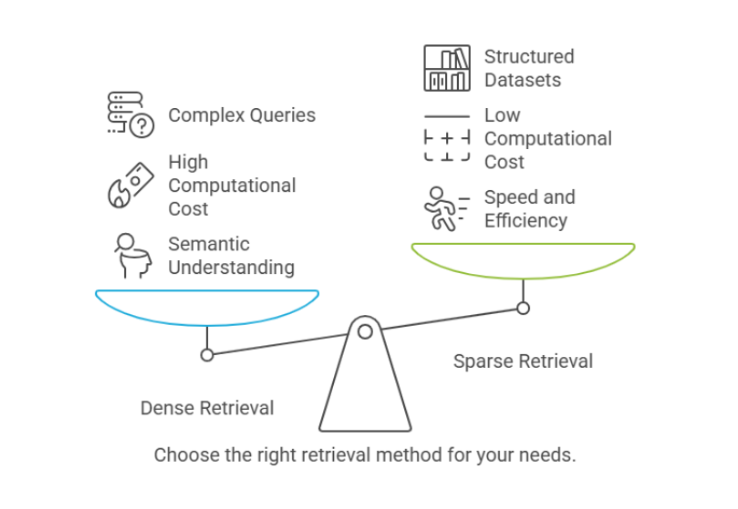
The Trade-offs Between Dense and Sparse Retrieval
Precision vs Recall
Sparse retrieval typically excels at precision, meaning it’s great at finding exact matches to the words you search for. It’s highly effective in scenarios where the terms you’re using are very specific and directly related to the documents.
Dense retrieval, on the other hand, is better at recall it’s able to pull in documents that might not match your keywords exactly, but are still highly relevant based on the overall meaning. This is especially useful when the terms you’re searching for are vague or vary in phrasing.
Speed and Efficiency
Sparse retrieval is faster because it only needs to look for exact matches. It’s a simple, rule-based approach that works well for smaller datasets or well-structured information.
Dense retrieval requires more computational resources since it involves complex neural networks to generate embeddings and compute vector similarity. This makes it slower but much more accurate in understanding complex or varied queries.
Domain Dependence
Sparse retrieval works best in well-defined, structured domains, like product catalogs or legal databases, where terms are more standardized.
Dense retrieval shines in domains with a lot of ambiguity, such as research papers, social media, or customer support logs, where similar concepts can be expressed in many different ways.
Real-Life Example: Enterprise Search System
Imagine a company that’s building an internal search system to allow employees to quickly find HR policies. The documents are highly structured and include clear terms like “leave policy” and “employee benefits.”
Sparse retrieval would work well here because the terms are predictable and the search can focus on exact matches.
However, if employees start asking questions in natural language—such as “How many vacation days do I get?” or “What are the rules for taking time off?” the system might not find the relevant policies easily.
Here, dense retrieval would be a better option. It could understand that “vacation days” and “leave policy” are related concepts, returning the correct document even if the exact terms aren’t used.
When to Use Each Approach
Use sparse retrieval when:
You have highly structured data with clearly defined terms.
Speed and efficiency are top priorities.
You’re working with smaller datasets or specialized domains.
Use dense retrieval when:
You need to understand the meaning behind complex or varied queries.
Precision isn’t as critical as recall.
You’re working with large, unstructured datasets or need to handle diverse language.
Hybrid Models: The Best of Both Worlds
In many real-world applications, combining both dense and sparse retrieval can yield the best results. For instance, you could use dense retrieval to capture the broad meaning of a query and sparse retrieval to quickly narrow down the results to specific documents. This hybrid approach helps balance accuracy with speed.
5. Implementing Dense Retrieval in Your Projects
Now that we’ve covered the theory behind dense retrieval, let’s take a look at how you can implement it in your own projects. Whether you're building a search engine, a knowledge management system, or a chatbot, integrating dense retrieval into your workflow can significantly improve your results. Here’s a step-by-step guide to help you get started.
Quickstart with FAISS or Haystack
There are several tools and libraries available to help you implement dense retrieval without reinventing the wheel. Let’s explore two of the most popular options: FAISS and Haystack.
FAISS: Fast Approximate Nearest Neighbor Search
FAISS is an open-source library from Facebook AI designed for similarity search and clustering. It allows you to store and retrieve high-dimensional vectors efficiently, making it ideal for dense retrieval.
Install FAISS:
If you’re using Python, you can install FAISS via pip:
pip install faiss-cpu
Or, for GPU acceleration:
pip install faiss-gpu
Create Embeddings:
You’ll first need a model to convert your documents into embeddings. A popular choice is Sentence-BERT, which is optimized for generating sentence embeddings.
For example, you can use the transformers library to load a pre-trained BERT model and convert text to embeddings.
Index the Vectors:
Once you have your embeddings, FAISS helps you index them. This process involves creating a data structure that allows for fast retrieval based on vector similarity.
Example:
import faiss
index = faiss.IndexFlatL2(d) # 'd' is the dimensionality of your embeddings
index.add(embeddings) # Add the document embeddings to the index
Query the Index:
You can then query the index with a new query embedding and retrieve the closest matches. FAISS will return the documents with the most similar vectors.
Example:
D, I = index.search(query_embedding, k=5) # Retrieve top 5 closest documents
Haystack: A Framework for Building Search Systems
Haystack is another powerful open-source framework for building search systems with dense retrieval capabilities. It integrates with models like DPR and Sentence-BERT, and supports end-to-end pipelines for document retrieval and question answering.
Install Haystack:
To get started with Haystack, simply install the library:
pip install farm-haystack
Set Up a Simple Pipeline:
Haystack provides pre-built components like retrievers, readers, and document stores. You can quickly set up a dense retrieval pipeline using a retriever like DPR.
Example:
from haystack.nodes import DensePassageRetriever
from haystack.utils import fetch_archive_from_http
from haystack.document_stores import FAISSDocumentStore
# Initialize a document store
document_store = FAISSDocumentStore(faiss_index_factory_str="Flat")
# Set up the retriever
retriever = DensePassageRetriever(document_store=document_store)
# Add documents to the store
document_store.write_documents(documents)
# Query the retriever
retriever.retrieve("What is dense retrieval?")
Deploying the System:
Once your model is trained and the system is set up, you can deploy it as a REST API, integrate it into a chatbot, or use it in a web application to provide powerful document search capabilities.
Real-Life Example: Building a Personal Knowledge Assistant
Let’s say you’re a productivity enthusiast and want to build a personal knowledge assistant. You have a large collection of notes, articles, and resources, and you want a system that can help you find relevant information quickly.
Step 1: Use Sentence-BERT to generate embeddings for your notes.
Step 2: Index these embeddings using FAISS for fast similarity search.
Step 3: When you ask the assistant a question, it converts your query into an embedding, searches for the most relevant documents, and presents them to you.
This simple system can save you hours of manual searching and help you get the exact information you need in seconds.
6. Dense Retrieval in Action: RAG, Chatbots & Beyond
Dense retrieval isn’t just a theoretical concept it’s already being used in a variety of applications to improve how we access and interact with information. From chatbots to advanced search engines and even in cutting-edge Retrieval-Augmented Generation (RAG) models, dense retrieval is transforming industries and making information retrieval smarter and more efficient.
Chatbots and Virtual Assistants
One of the most exciting uses of dense retrieval is in chatbots and virtual assistants. Traditional chatbots often rely on pre-programmed responses or keyword matching to answer questions. This can work well for simple queries but falls short when the questions get more complex or when phrasing varies.
Dense retrieval allows chatbots to understand the meaning behind the user’s question, even if it’s phrased differently from the pre-defined responses. Here’s how it works:
User Query: A user asks a question like, “What’s the process for requesting time off?”
Query Embedding: The query is converted into an embedding, representing its meaning.
Search: The system uses dense retrieval to search through a database of HR policies, finding documents that explain the time-off request process, even if the terms don’t match exactly.
Response Generation: The chatbot then generates a response based on the most relevant documents retrieved.
This approach allows chatbots to handle a broader range of questions and provide more accurate, contextually relevant answers. For example, a user might ask, “How many vacation days do I get?” and the chatbot could still pull up the correct document, even though the query is different from the stored information.
Retrieval-Augmented Generation (RAG)
RAG is an advanced technique that combines retrieval with generation to provide more contextually rich answers. Instead of simply retrieving documents, RAG models generate an answer based on the retrieved documents, offering an even more refined response.
Here’s how RAG works:
Retrieval: First, the system retrieves the most relevant documents using dense retrieval, just like we’ve discussed.
Generation: Then, instead of just returning a snippet or excerpt from the document, the system uses a generative model (like GPT) to create a concise, coherent answer based on the retrieved information.
This is particularly useful in domains like customer support or legal research, where users need highly specific and detailed answers.
Search Engines and Document Databases
Dense retrieval is also being integrated into modern search engines, improving how users interact with vast databases of documents. Unlike traditional search engines, which match keywords, semantic search engines use dense retrieval to deliver more contextually relevant results. This has profound implications for industries like:
Healthcare: Quickly retrieving medical research papers, clinical guidelines, or patient records by understanding the medical terms and context, rather than relying on keyword matching.
Legal Research: Lawyers can find relevant case law or statutes even if the documents don’t use the exact terms they’ve searched for. Dense retrieval allows the system to understand legal principles and return more meaningful results.
Real-Life Example: Implementing Dense Retrieval in Legal Tech
Imagine a legal tech startup developing a document search engine for law firms. The goal is to help lawyers quickly find case laws and regulations that are relevant to their current cases.
Step 1: They use Sentence-BERT to generate embeddings for thousands of legal documents.
Step 2: The documents are indexed using FAISS for fast retrieval.
Step 3: When a lawyer asks about a specific case, the system searches for documents that contain semantically similar concepts, even if the exact terms don’t match.
Step 4: The system can also use RAG to generate a summary of relevant legal precedents, helping the lawyer quickly grasp the context of the case.
This setup significantly speeds up the legal research process and helps professionals find relevant documents much faster than relying on traditional keyword-based search systems.
7. Conclusion and Next Steps
Dense retrieval is transforming the way we search for and interact with information. By moving beyond simple keyword matching and leveraging machine learning models that understand the meaning of words and phrases, dense retrieval provides more accurate, contextually relevant search results. From chatbots and legal tech to cutting-edge Retrieval-Augmented Generation models, the impact of dense retrieval is already being felt across various industries.
Why Dense Retrieval Matters
As information grows increasingly vast and complex, traditional search methods simply aren’t enough. Dense retrieval allows systems to:
Understand context: It grasps the meaning behind the words, helping you find relevant documents even when exact terms don’t match.
Provide more accurate results: By focusing on the intent behind the query, dense retrieval ensures that users get the information they actually need, not just the information that matches keywords.
Improve efficiency: Although it’s more computationally demanding than sparse retrieval, dense retrieval can save time by delivering more relevant results upfront, avoiding the need for multiple searches.
Next Steps for Implementing Dense Retrieval
If you’re looking to integrate dense retrieval into your own projects, here are some actionable next steps:
Understand Your Use Case: Determine the type of content you’re working with whether it’s structured or unstructured—and decide whether dense retrieval is the best fit for your project.
Choose the Right Tools:
Use libraries like FAISS or Haystack to implement dense retrieval easily.
For large-scale systems, consider platforms that support dense retrieval at scale, like Weaviate or Elasticsearch with vector search support.
Build a Prototype: Start by implementing a small-scale prototype to experiment with different models, such as Sentence-BERT or DPR, and evaluate their performance based on your specific needs.
Optimize Performance: Dense retrieval models can be resource-intensive. Make sure to fine-tune them for speed and efficiency, particularly if you’re working with large datasets or real-time systems.
Stay Updated: The field of dense retrieval is rapidly evolving, with new models, tools, and research emerging regularly. Stay on top of the latest developments to ensure your system remains competitive and effective.
Final Thoughts
The potential applications for dense retrieval are vast, from improving search engines and recommendation systems to revolutionizing customer service and legal research. As this technology continues to evolve, it’s becoming increasingly important for professionals and developers to understand how it works and how to leverage it effectively.
By integrating dense retrieval into your projects, you can create smarter, more intuitive systems that truly understand user intent and provide the most relevant results. Whether you’re building an enterprise search tool, a chatbot, or a research assistant, dense retrieval is a powerful technology that can help you meet the demands of modern, data-driven applications.